Linux kernel Rust module for rootkit detection
This work was part of an internship at Thalium on the subject of kernel-level malware detection in Rust on Linux.
Source code related to this article can be found in the following repositories:
- Linux-next branch with some custom patches
- Rust Linux Kernel Module designed for LKM rootkit detection
Context
Linux systems are used in a wide variety of environments, from IoT to security critical servers. Therefore, they are a common target for attackers and there is a need for malware detection on those systems.
We can identify two distinct uses of such detection:
- Monitoring purposes: The goal is to detect the infection as soon as possible, ideally with an immediate response. This is commonly referred to as EDR (Endpoint Detection and Response).
- Forensic purposes: The goal in this case is to gather as much relevant information as possible post mortem (i.e. after the infection has occured), to understand what happened and how.
There is a vast variety of malware, which makes the task of detecting all of them quite extensive and unrealistic to accomplish within a 6-month internship.
Nevertheless, attackers often follow a common pattern when compromising a vulnerable machine, be it to install a keylogger, deploy a botnet worker, or gain access to data: they want to keep a persistent and reproducible access to the system.
This persistent access is typically obtained by using a type of malware called a rootkit. Detecting rootkits can be an efficient and generic way to determine that a system has been compromised. Hence, this article is dedicated to rootkit detection.
As stated in a 2024 paper by Jacob Stühn et al., there is a need for more modern rootkit detection software for Linux, as the existing open-source tools are quite old and less performant.
In the following, I will mostly focus on the detection of kernel rootkits, which I find the most interesting. However, the developed tool integrates detection techniques for other types of rootkits (namely user space and eBPF rootkits).
Rootkit capabilities
A rootkit commonly offers the following capabilities (extracted from the open-source Reptile rootkit’s features):
- Hiding itself: the rootkit shouldn’t be detectable by a system administrator
- Hiding data: whether it is a part of a file’s contents, an entire file, or a process, this capability is useful to hide other malwares
- Reverse root shell: often paired with connection-hiding capabilities (such that open ports are invisible, or that network monitoring tools do not show any traffic)
- Boot persistence
Now that we understand our target, let’s learn about the tools we will use.
How the Linux kernel API helps us for malware detection
An intuitive approach is that the higher the privilege level of our EDR, the harder it becomes for malware to bypass it, and the more capabilities we will have to observe malware behavior and take action. This is why it is beneficial to place our EDR in the kernel.
We can note that kernel-level rootkits have the same privilege level as us, so a kernel rootkit that is conscious of our tool can bypass it, and all we can hope is just to make its life harder.
A solution to this problem is to develop at hypervisor level — but even then, there exist hypervisor-level rootkits (e.g. Blue Pill) and UEFI-level rootkits (e.g. LoJax).
Running code in the Linux kernel
As most kernels, Linux offers the possibility to dynamically load code in the kernel. This interface is called loadable kernel modules (or LKM) and is most often used to dynamically load drivers for hardware, although it can be used to develop detection tools.
The classic way to develop a LKM is in C, using the API exposed by the kernel which can be found, for the most part, in the include/ folder of the source. Its documentation can be found here. However, as developing in the kernel is most of the time a RTFC (Read The Fine Code) experience, the Elixir Cross Referencer will more often than not come in handy.
The CrowdStrike incident showed that a mistake in the development of a kernel-level EDR can have catastrophic repercussions. Even though, in the CrowdStrike case, the problem arose from a logic bug, a simple memory issue could lead to the same result. Therefore, it would be safer to develop our tool in a language that gives more guarantees about the correctness of our program than C. For that, Rust is a good candidate.
Luckily for us, recently (around 2020) a new interface to develop kernel modules is being worked on by the Rust for Linux project. The main goal of this interface is to be able to develop Linux kernel modules in fully safe and idiomatic Rust. We will discuss this new kernel interface a bit more in the second part of this article.
Tools provided by the kernel
Data analysis
When running code in the kernel, we gain access to the structures of all subsystems present. This is particularly useful to monitor the state of the kernel and detect abnormal states.
Tracing
Another useful tool the kernel gives us access to is tracing APIs. Concretely, a tracing API lets you place callbacks, called probes, at certain points in the kernel that take as argument a context. These probes will then be called when those points are reached.
The Linux kernel offers a lot of tracing APIs (a full documentation can be found here). Let’s do a quick review of the most generic and common ones to understand their use-cases:
- Tracepoint: In this API, the places we can probe are statically defined. This has the advantage of a really low overhead, and we can also control the passed context (since it is defined by the developer who put the tracepoint). However, the probing points are limited.
- Fprobe: This API allows us to place probes on almost every function of the kernel, at entry and return. The passed context is the register trace at the entry and exit of the function.
- Kprobe: This one lets us probe any address of the kernel (not only the beginning or return of functions). As with fprobe, the context passed is the register trace at the probed point. However, it works by putting breakpoints at the probed point, so the overhead is quite high.
- Uprobe: This one is quite different from the others because it allows us to put breakpoints on any executable in the filesystem, which makes it the only tracing utility to be able to probe user space programs from the kernel. The context passed is also the register trace.
To monitor the kernel for security purposes, the fprobe API is a reasonable choice as it gives a lot of freedom with a lesser overhead than kprobe, and probing start and exit of functions is sufficient for our use case. Hence, this is the API that I used in my tool.
For security monitoring purposes, the uprobe API is also really interesting, however I focused mainly on the detection of kernel rootkits. Furthermore, the kernel-side uprobe API is neither straightforward to use nor well-documented.
Now that we have all the available tools and a defined target, let’s see how we can detect it.
Detecting LKM rootkits
To accomplish this, the approach I chose was to analyze their inner workings and deduce checks to implement. To do that, we need some samples to work with:
However, working on a recent Linux version (6.12) due to using Rust, only the first two rootkits were compatible and could be leveraged to assess the effectiveness of our tool.
Registration
On Linux, kernel-level rootkits are subject to the same constraints as our tool if they want their code to be executed in the kernel, and remain persistent: they have to use the LKM interface.
More specifically, this means that their only method of loading code into the kernel is through the init_module syscall family (more commonly used through the insmod or modprobe commands)."
This statement wasn’t always true: before the
/dev/kmeminterface was removed, one could load a kernel module using this device file. However, this interface has been deactivated by default as of Linux 2.6.26 and permanently removed since 2021 (source).
Therefore, we can easily monitor the loading of every kernel module and potential rootkit, dump their name, analyze their executable, and calculate a hash of it. I did it by probing the do_init_module function which is called by all the init_module syscall types.
This probe successfully detects the installation of our two kernel rootkit samples, but their hash can be effortlessly changed, which makes this test easy to bypass. Furthermore, this check will detect all module loadings indifferently.
Registration structures
We saw that the loading of a kernel module, by itself, is not enough to determine whether it is malicious.
If we read further what the loading routine of an LKM does, we can roughly summarize it as the following steps:
- Allocate memory for the module’s text and data
- Register the module in three different structures:
- Jump to the init function of the module
The registering part is what allows us to list modules using lsmod for example. Hence, kernel rootkits will often seek to remove themselves from these quite bothersome structures.
However, we can observe that several open-source examples of rootkits fail to do so completely, as they often forget one structure to remove themselves from:
Reptiledoesn’t remove itself from themkobjstructureDiamorphineremoves itself only from themod_liststructure
What we can do is verify the consistency of these registration structures, which allows us to detect Reptile.
Brute-forcing the module address space
What if a rootkit successfully removes itself from all these structures? That is, for instance, what the KoviD rootkit achieves.
A solution was proposed in a 2024 Phrack article. The idea is based on what happens in the allocating memory step. If we read further the code of this step (and look a bit into the ELF organization of an LKM), we can draw the following diagram:
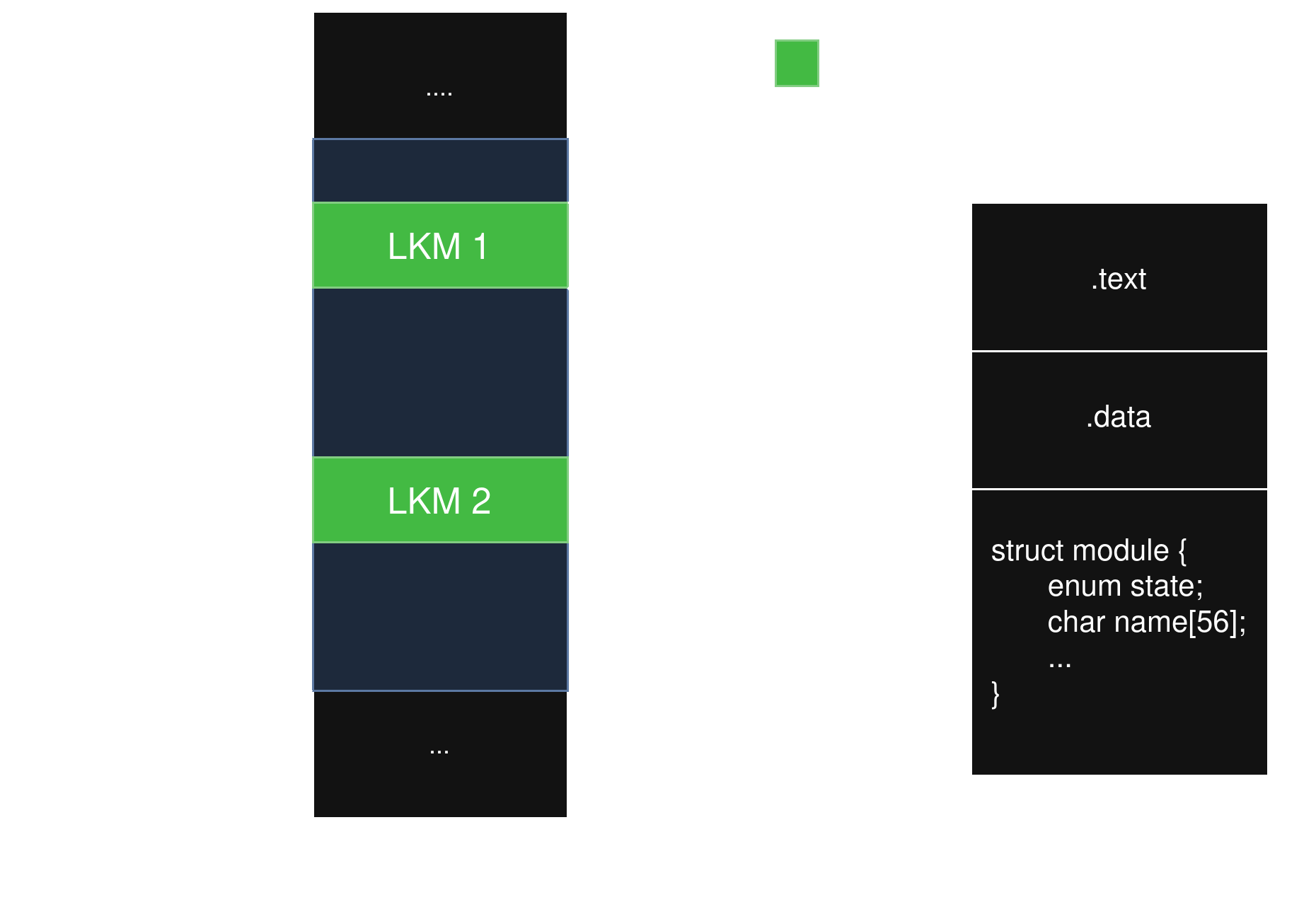
The kernel allocates memory for the LKMs in a specific address range (source) and, for each LKM, it places the .text section, followed by the .data section, and finally it appends a structure of type struct module that describes the LKM.
This structure is particularly interesting because some of its fields have known valid ranges, namely:
state: an enum between 0 and 3name: a null-terminated, non-empty string of 56 charactersinitandexit: pointers into the LKM address range or nullcore_layout.size(size of the.textallocation): a non-zero multiple ofPAGE_SIZE
Using this information, we can iterate through the LKM address range and try to match each allocated and aligned memory address with a struct module using the criteria we defined above. This gives us a way to find all the LKM structures. If we verify that each found LKM is correctly registered in the structures, we can detect suspicious modules.
This check allows our tool to detect both Reptile and KoviD.
Detection using kallsyms API calls
Once a kernel rootkit is successfully loaded, it will try to gain access to some structures in the kernel to tamper with. But there is a small problem with that: when developing an LKM, you only have access to the exported symbols (those exported using the EXPORT_SYMBOL family of macros), and most of the interesting symbols for kernel rootkits are not exported.
A solution to this problem is to use the kallsyms_lookup_name function, which allows searching for the address of a given symbol.
We can observe that this function is not used a lot throughout the kernel source, and never used in a kernel module.
Plus, we can observe some common symbols that are used by rootkits, for instance:
mod_tree_removewhich allows you to remove yourself from themod_treestructure;- some syscalls, such as
__x64_sys_getdents64, which lets you list files in a directory.
Using this information and the calling address the fprobe API gives us access to, we can create a detection rule: if kallsyms_lookup_name is called by a module (i.e. the calling address is in the kernel’s module address range), this is a suspicious usage (and even more so if the looked up symbol is commonly used by rootkits).
Indirect calling
There is actually a problem with the previous technique: since 2020, kallsyms_lookup_name is not exported anymore, and thus kernel rootkits cannot rely on it anymore.
To overcome this problem, a new technique to find addresses of symbols appeared among Linux kernel rootkits: if we read the kprobe API documentation, we see that we can probe a point in the kernel by only indicating the symbol name, and the registering function will give us the address of the point probed.
In fact, if we read how kprobe implements address resolution, we can see that it relies on the kallsyms_lookup_name function behind the scene. So, good news for us: we can keep the same probe to detect symbol resolution, because it’s still the same function that is called underneath.
However, using this technique, the calling address of the function is in the kernel core. The module’s function call happens several calls prior to this point, so we need to climb up the stack and look at each calling addresses. Luckily for us, the kernel exports an API for unwinding the kernel stack, which we can leverage to check whether the stack trace contains an LKM address.
This check allows us to detect Reptile during its initialization phase.
Can
kallsyms_lookup_namebe used by other code than LKMs?Its main usage lies within the probing APIs. Something I didn’t mention was that all the probing APIs I presented earlier have a user space counterpart. This counterpart has reduced capacity (you can’t register any callback you want) and is mainly useful for debugging or performance profiling. This user space interface is managed by core kernel code.
Inline hooks detection
In order to exhibit actual capabilities (other than hiding itself), a rootkit needs at some point to modify the way the kernel behaves. The most common current solution is to place probes in the kernel and modify the passed context. To achieve this, there are two options.
1. Use a kernel probing API
Kernel probing APIs can be used to tamper with the state of the kernel at specific points (for example, by modifying the function parameters). This is easy to implement because the kernel provides all the necessary tools to do so.
However, this also means that all the probed points are managed by the kernel, and therefore, the kernel registers them somewhere accessible by every module — and even in some user space debug files.
The enabled_functions debug file, for instance, shows all the functions probed in the kernel. We can see in the following example how call_usermodehelper is probed:
call_usermodehelper (1) R tramp: 0xffffffffa0214000 (fprobe_handler+0x0/0x1c0) ->ftrace_ops_assist_func+0x0/0xe0
This is what KoviD does: therefore, monitoring this debug file allows us to detect it.
2. Use a custom probing framework (often called hooking framework)
This is a bit more difficult to put in practice. There are a few open-source tools for Linux kernel hooking (e.g. KHOOK) already, although you could also roll your own hooking framework.
But in either of these two cases, placing probes in the kernel implies modifying its text. Therefore, we can perform integrity checks on the kernel’s text in multiple manners:
- Hash check for a simple yes/no response
- Full byte-per-byte comparison for more information (which functions were hooked, where is the hook placed)
These integrity checks allow us to find Reptile and KoviD, but only if they were installed after our tool started.
Finding inline hooks installed before our tool is started
To be able to detect inline hooks even when they are installed before us, we can note that probing is performed by placing either a JUMP or an INT3 instruction at the beginning of a function, which is not something you would normally find there.
We can iterate through all the text symbols of the kernel (i.e. all functions) and check the first opcode. The kernel has a handy function for that: kallsyms_on_each_symbol. However, this function doesn’t give us access to the section information of the symbol. Therefore, we chose to reimplement our own symbol iterating function in Rust to get access to the section information.
Once we do that, we can verify that each function hasn’t been hooked by checking if their first opcode is not a JUMP, with the help of the in-kernel disassembler.
Why not also check for breakpoint instructions as some hooking techniques (e.g.
Kprobe) use these?The main reason is that while implementing this method, I discovered that breakpoint instructions were legitimately placed at the start of some functions, more specifically functions annotated with
__initor__exit. I suppose this allows to implement unloading of these functions, although I haven’t dug any deeper.
This check allows us to find Reptile, which leverages KHOOK to place JUMP instructions at the beginning of hooked functions.
Another technique which was really common consisted in modifying function pointers in various kernel structures. This technique had the advantage of being easy to implement and more discreet.
Most of the time, the target structure was
sys_call_table(the table for all the syscall handler function pointers), but since Linux 6.9, the syscall handling routine has been modified, and it is now done with a switch statement (written in the most C-esque way possible).It is still possible to tamper with other structures, but I have not found an open-source kernel rootkit that works only by modifying function pointers on a modern Linux kernel (so without
sys_call_table). I also tried to do it myself unsuccessfully.However, my tool still watches for rootkits that may tamper with
sys_call_tablebecause while it is not used anymore, it still exists for legacy purposes.
Developing a Rust kernel module: a review
The entire tool has been developed in Rust in the Linux 6.12 kernel. As the Rust for Linux project is still in its early stages, we give a review of the general experience of developing in the Linux kernel using Rust.
The goal of Rust for Linux
The main goal of the Rust for Linux project is to propose a fully safe and idiomatic Rust driver API in the kernel. In other words, the objective is to allow anyone to develop Linux kernel drivers (LKMs) in Rust, just like developing a Rust userspace application1, so it doesn’t involve rewriting core kernel code.
The environment
To fulfill its goal, the main effort of the project is focused on wrapping Linux’s C driver API in Rust such that the resulting API is safe and idiomatic, creating what is known as a Rust abstraction.
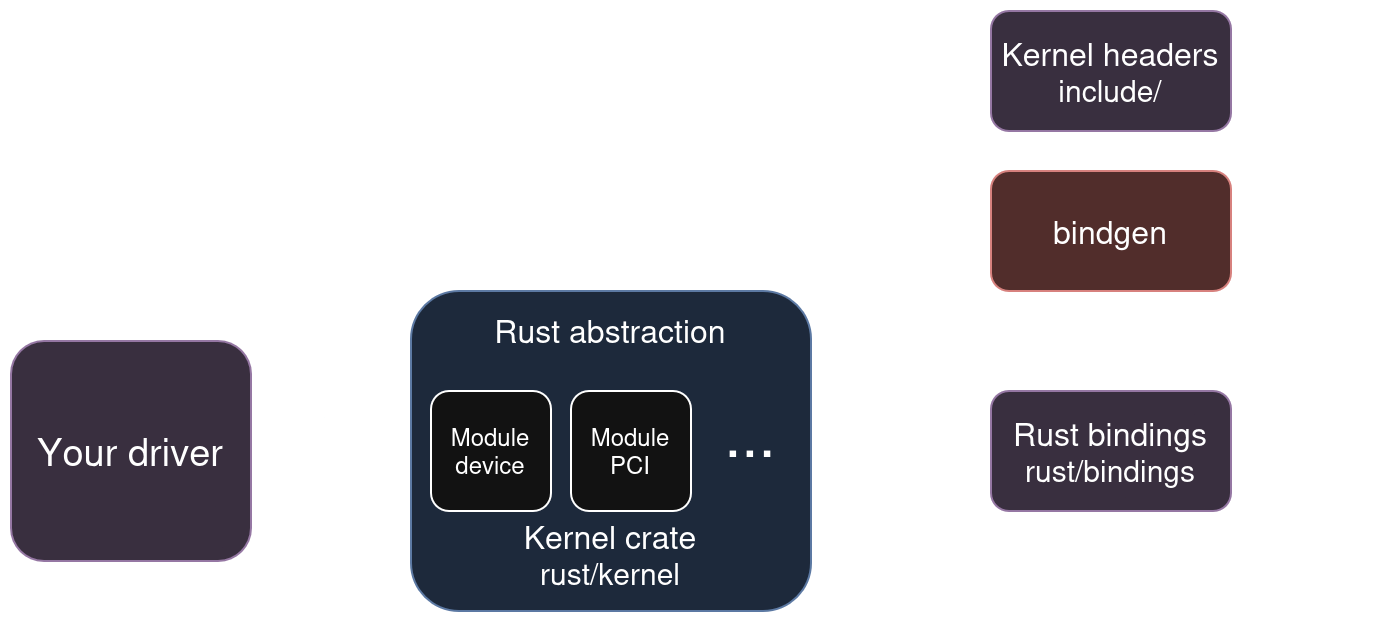
- The kernel’s C headers are transformed into Rust
unsafefunction declarations and structure definitions. This step is automatically done by thebindgentool. - Unsafe functions are wrapped by abstractions in the kernel Rust crate.
- The driver’s code is written by calling safe functions from the kernel crate. Although developers have access to the bindings generated by
bindgen, they shouldn’t use them and instead merge the Rust abstractions they are missing in the kernel crate such that no FFI calls is directly made from the driver.
State of the Rust for Linux project (as of February 2025)
In practice, the Rust for Linux project is still relatively new and takes time to progress (mainly because a lot of attention is given to designing abstractions). Therefore, as of now and for the foreseeable future, the experience of developing in Rust in the kernel involves writing many abstractions yourself, which is a tedious process. For example, for my tool, I notably had to implement abstractions for:
- the
fprobeAPI; - the
insnAPI (disassembler); - the module management API.
Though, during the course of my six-month internship, the project has made significant progress and the number of available abstractions has almost doubled, with major ones being merged:
miscdevice: to create generic device files for driver ↔ user space communicationPCIandplatformbus APIs: to create drivers for hardware relying on these busesioAPI: to communicate with hardware
In consequence, a few drivers have been merged: two PHY device drivers, and the beginning of a new driver for NVIDIA GPUs (Nova).
When talking to people about Rust for Linux, some seem to think that the project is in bad shape, and some believe it will die (for example because of resignations). Here is my perspective on the matter.
Overall, the project is doing great. First, it has the backing of Greg K-H, the person responsible for everything driver-related in the Linux kernel, which makes it difficult for any individual to completely block its progress.
In fact, many interactions with C kernel maintainers have been really positive. They often show interest in Rust and seem to appreciate that the Rust for Linux project is working on abstractions for their subsystems (see, for example, the questions from
mmsubsystem maintainer Lorenzo Stoakes in this thread).Furthermore, some major abstractions have been merged. The
PCIandplatformabstractions, for instance, are important milestones. We are also seeing RFCs for drivers appearing on the Rust for Linux mailing list, indicating that the project is starting to fulfill its goal! Unfortunately, these successes are rarely talked about.
Is writing drivers in Rust worth it?
While adding Rust to the kernel is a lot of work, I found that there were multiple benefits.
Typing system
The main advantage of Rust is its type system. It is one of the few languages that will give you access to such a complete type system (be it structured types or lifetime expressions) — and at the same time, if you believe you do know better than the compiler, it allows you to bypass it explicitly by encapsulating the code in an unsafe block.
For example, we can compare a structure Foo with a field of type struct Bar protected by a mutex, in both C and Rust:
C
struct Foo {
struct Bar bar;
mutex bar_mutex;
}
Rust
struct Foo {
bar: Mutex<Bar>,
}
Although in this example, is seems obvious that in the C version the mutex is related to the bar field, nothing really enforces it and prevents you from forgetting to take or release it. Even if it comes with documentation, the risk of having inconsistencies between the documentation and the actual code is still there.
Whereas in the Rust version, it is impossible (at least without unsafe) to access the Bar structure without taking the mutex — and the lifetime system guarantees you that the lock will be released automatically when you don’t need it anymore.
This is a simple example featuring a structure and a single field, but many kernel structures have dozens of fields, and their synchronization requirements are rarely documented2, which makes implementing them in Rust even more beneficial. Rust’s benefits also extend to functions, making the API more explicit without requiring additional documentation.
Safety
I believe the safety argument is secondary for two reasons: first, wrapping C APIs in Rust doesn’t make them any safer, and second, Rust’s safety argument primarily comes from its type system because, as we saw, it enforces a good usage of those APIs.
Since Rust excels at enforcing requirements at compile time (be it lifetime or usage requirements), writing your driver in Rust almost guarantees that you won’t introduce issues by misusing the kernel API (which is a common source of bugs and vulnerabilities).
Linting
Because Rust is more explicit than C, it also enables better linting, which is used in the kernel:
- All unsafe code must be justified with a
SAFETYcomment indicating how all the safety conditions are upheld. - Public APIs (marked with the
pubkeyword) must include documentation written in therustdocformat. As a result, the kernel’s crate documentation follows the same format as any other Rust crate, making it easier to understand for developrs coming from a Rust background.
And if you’re still not convinced, you can go take a look at the error handling code of
load_moduleand remember that in Rust, all the failure checks and cleaning steps could be replaced by simply appending a?on each function call.
Conclusion
In this post, we walked through the development of a malware detection tool in Rust (which you can find on Github) and we explored a few rootkit techniques.
Since monitoring capabilities of LKMs are not a primary focus of the Rust for Linux project, many abstractions had to be reimplemented, but I still enjoyed writing my tool in Rust. I found that the Rust documentation and abstractions are way easier to work with than their C counterparts.
Overall, I believe the goal of making driver development more accessible with the introduction of Rust will be achieved.
Although adding a new language in the kernel involves significant work and may complicate the maintenance of the C API, the long-term benefits, such as simplifying driver development and accelerating code reviews for maintainers, will largely offset these challenges. They won’t need to correct API usage, or check if resources are properly freed for instance, and sections requiring extra care (such as unsafe blocks) will be explicitly marked.